PhD Research Overview
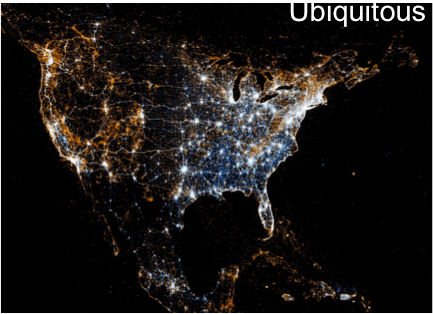
Context and motivation. The information explosion propelled by the advent of online social media, the Internet, and the global-scale communications has rendered statistical learning from data increasingly important. At any given time around the globe, large volumes of data are generated by today's ubiquitous communication and mobile devices such as cell-phones, surveillance cameras, e-commerce platforms, and social-networking sites. For instance, the map of North America shown above was generated by drawing a snapshot of dots at locations where a picture was taken and uploaded to Twitter.

The term `Big Data' is coined to precisely describe this information deluge. Quoting a recent article published in The Economist `The effect (of Big Data) is being felt everywhere, from business to science, and from government to the arts'. Mining information from unprecedented volumes of data promises to facilitate learning the behavioral dynamics of emergent social-computational systems, and also protect critical infrastructure including the smart grid and Internet's backbone network. But great promises come with formidable research challenges; as Google's chief economist explains in the same article `Data are widely available, what is scarce is the ability to extract wisdom from them.' While significant progress has been made in the last decade towards achieving the ultimate goal of `making sense of it all,' the consensus is that we are still quite not there.

A major hurdle is that massive datasets are often messy, noisy and incomplete, vulnerable to cyber-attacks, and prone to outliers, meaning data not adhering to postulated models.(The name of the world's top soccer player Lionel Messi is misspelled in the picture, probably due to an outlier.) Resilience to outliers is of paramount importance in fundamental statistical learning tasks such as prediction, model selection, and dimensionality reduction. In particular, the widely adopted least-squares (LS) method is known to be very sensitive to outliers. My current research deals with robust learning algorithms that are resilient to outliers, and contributes to the theoretical and algorithmic foundations of Big Data analytics.
Research at-a-glance and contributions. Modern data sets typically involve a large number of attributes. This fact motivates predictive models offering a sparse, meaning parsimonious, representation in terms of few attributes to facilitate interpretability. Recognizing that outliers are sporadic, the present research establishes a neat link between sparsity and robustness against outliers, even when the chosen models are not sparse. Leveraging sparsity for model selection has made headways across science and engineering in recent years, but its ties to robustness were so far unknown. A main contribution is that controlling sparsity of model residuals leads to statistical learning algorithms that are scalable (hence computationally affordable), and universally robust to outliers. Focus is placed on robust principal component analysis (R-PCA), a novel computational method devised to extract the most informative low-dimensional structure from (grossly corrupted) high-dimensional data. Scalability is ensured by developing low-complexity online and distributed algorithms that build on recent advances in convex optimization. Universality of the developed framework amounts to diverse generalizations not confined to specific: i) probability distributions of the nominal and outlier data; ii) nominal (e.g., linear) predictive models; and iii) criteria (e.g., LS) adopted to fit the chosen model.
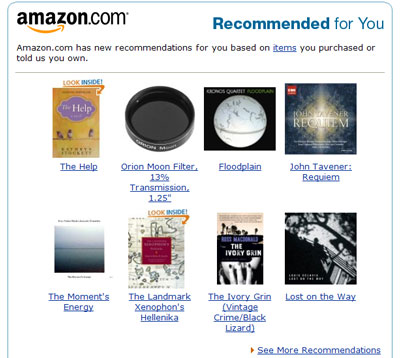
Major results of this research impact everyday life in human-computer interactions, including online purchases aided by e.g., Amazon's automated recommendations. These suggestions could be biased however, even if only a few negative product ratings introduced by `social liars', or malicious actors with commercially-competing interests, go undetected. The low-dimensional data model of (possibly corrupted) ratings advocated by R-PCA offers a natural fit, since it is now well accepted that consumer preferences are dictated by just a few unknown latent factors. In a related context, remarkable results were obtained in collaboration with faculty from the Dept. of Psychology, when using R-PCA to reveal aberrant or otherwise invalid responses in web-based, self-administered personality assessment surveys. This addresses a timely pressing issue in psychometrics, since `workhorse methods' used for traditional pencil-and-paper questionnaires are now deemed overly stringent and computationally intensive for online data screening.
This research offers also pioneering approaches to robust learning from network data. In this context, traffic spikes in the Internet, power consumption glitches across the power grid, or, agents exhibiting abnormal interaction patterns with peers in social networks can be all reinterpreted as outliers. Much of the challenge in analyzing network data stems from the fact that they involve quantities of a relational nature. As such, measurements are typically both high-dimensional and dependent. Distinct from prior art, the developed algorithms can process network information streams in real time, and are flexible to cope with decentralized data sets that cannot be communicated and processed centrally due to security, privacy, or memory constraints. Leveraging these online and decentralized features, yields an innovative approach to unveiling Internet traffic anomalies using real-time link utilization measurements. The novel ideas here are to judiciously exploit the low-dimensionality of end-to-end network flows and the sparse nature of anomalies, to construct a map of anomalies across space and time. Such a powerful monitoring tool is a key enabler for network health management, risk analysis, security assurance, and proactive failure prevention. The proposed algorithms markedly outperform existing approaches, that neither account for the network structure (they focus on isolated link measurements), nor they capitalize on the sparsity of anomalies.
Performance assesment. In addition to being scalable, the developed learning algorithms offer (analytically) quantifiable performance. To gauge the effectiveness of the proposed robust methods and corroborate the derived theoretical performance guarantees, extensive experiments were conducted with computer-generated synthetic data. These are important since they provide a `ground truth,' against which performance can be assessed by evaluating suitable figures of merit. Nevertheless, no effort of this kind can have impact without thorough testing, experimentation, and validation with real data. To this end, tests on real video surveillance, social network, Internet traffic, electric grid load curve, and personality assessment data were conducted to compile a comprehensive validation package.
For more details, please check my publications.