
Contributors
- Sponsor: Valerie Carey (circlestar)
- Instructor: Cantay Caliskan
- Qike Jiang, Yuewen Yan, Yang Zhang, Mark(Ke) Xu
- Goergen Institute for Data Science and Artificial Intelligence
Abstract
As AI tools enter hiring, understanding how they interpret resumes is critical. We studied how machine learning models and LLM APIs classify resumes and infer experience, using 2,484 samples across 24 job categories. Models like DistilBERT and ChatGPT-4.1 performed well on clear roles but struggled with overlapping fields and sometimes produced invalid labels. Our findings reveal key biases and offer insights for improving AI-driven hiring.
Introduction
Advancements in Large Language Models (LLMs) have revolutionized HR recruitment, offering rapid and efficient resume screening compared to traditional methods [2]. However, how LLMs interpret resumes and determine candidate suitability remains unclear.
This study explores how LLMs interact with resume data and identifies crucial factors influencing their decisions. We also examine effective strategies for job seekers to tailor resumes, optimizing their chances to stand out and avoid mismatches in automated screening.
“Sometimes the knowledge we really need isn’t contained in the questions we know to ask.” — Valerie Carey
Data & Exploratory Analysis
Sourced from Kaggle and compiled by Snehaan Bhawal (2021), the dataset contains 2,484 resumes grouped into 24 job categories [1]. Each sample includes a unique ID, the raw text version, an HTML-structured version, the ground truth label, and the predicted category.
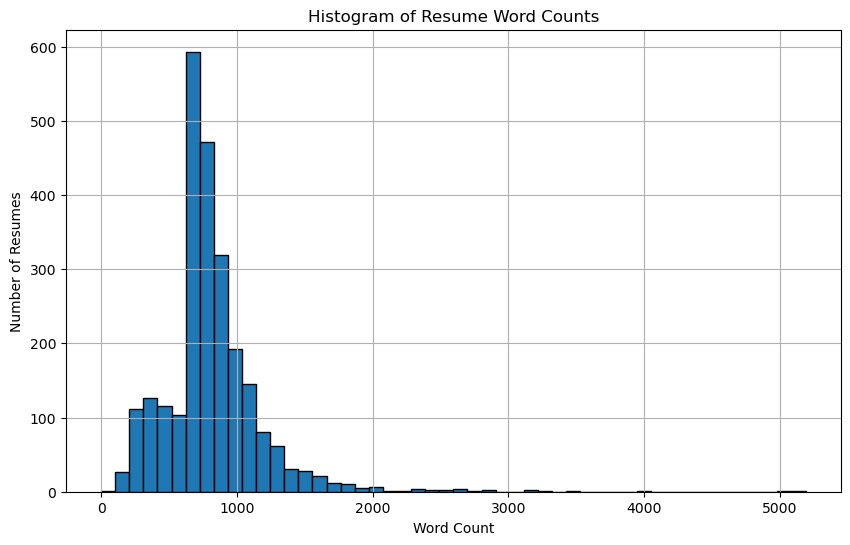
The pie chart represents the distribution of resume categories in our dataset. In histogram, we see that most resumes have 500–1,000 words, with a peak around 700 words; a few outliers exceed 2,000 words.

As part of our exploratory data analysis, we trained an XGBoost model to serve as a benchmark for evaluating the accuracy of LLM predictions across different categories.
Methods
Resume Category Classification & Evaluation
- We used three large-language models (GPT-4o, GPT-4.1, and DeepSeek V3, distillBERT) to assign each resume to one of 24 predefined job-function categories (e.g., HR, Finance, Engineering). Each resume’s “Resume_str” text was sent to the models, the single-word prediction capture.
- Accuracy, cost are parallel compared. The result is then visualized as a heat graph, the misclassification by LLM will be carefully further evaluated.
Experience Estimation and Level Classification
- We used GPT-4o to estimate total years of experience and career level (Entry, Mid, Senior, Executive) for each resume.
- A standardized prompt generated structured JSON outputs, enabling automated labeling across 2,484 resumes.
- These results supported our analysis of experience distributions, career ranges, and dominant keywords by level.
Results
Result – Resume Category Classification & Evaluation
Most classification shows reliable, however all three LLMs showing very similar misclassification on certain type of jobs:
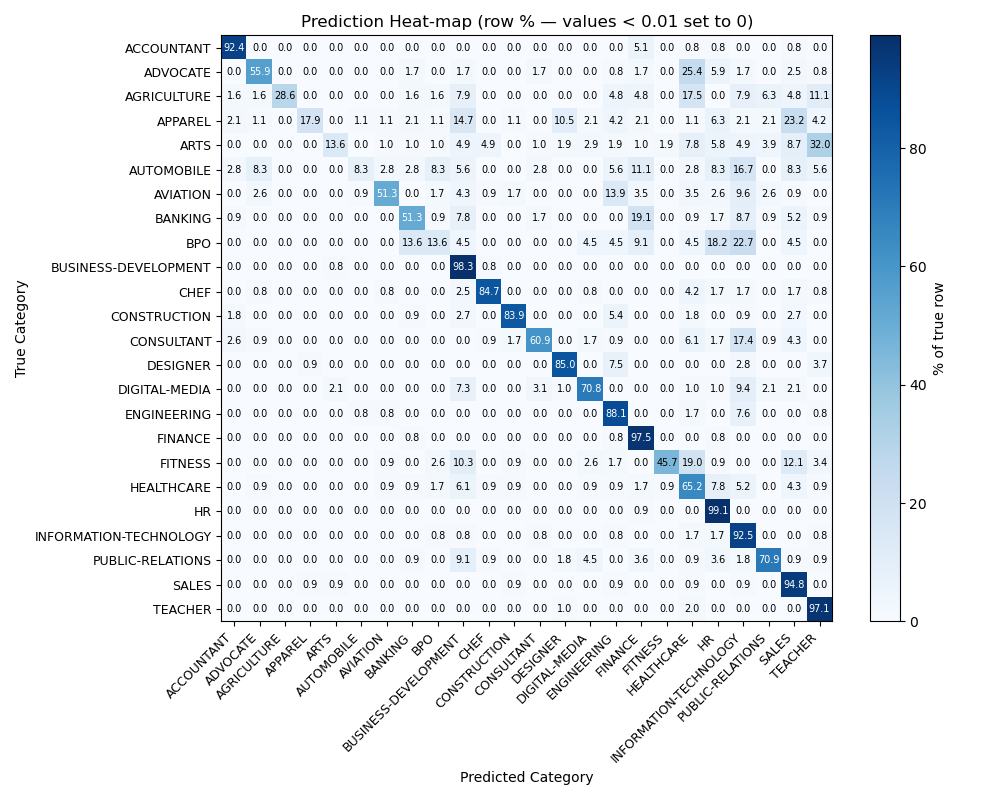
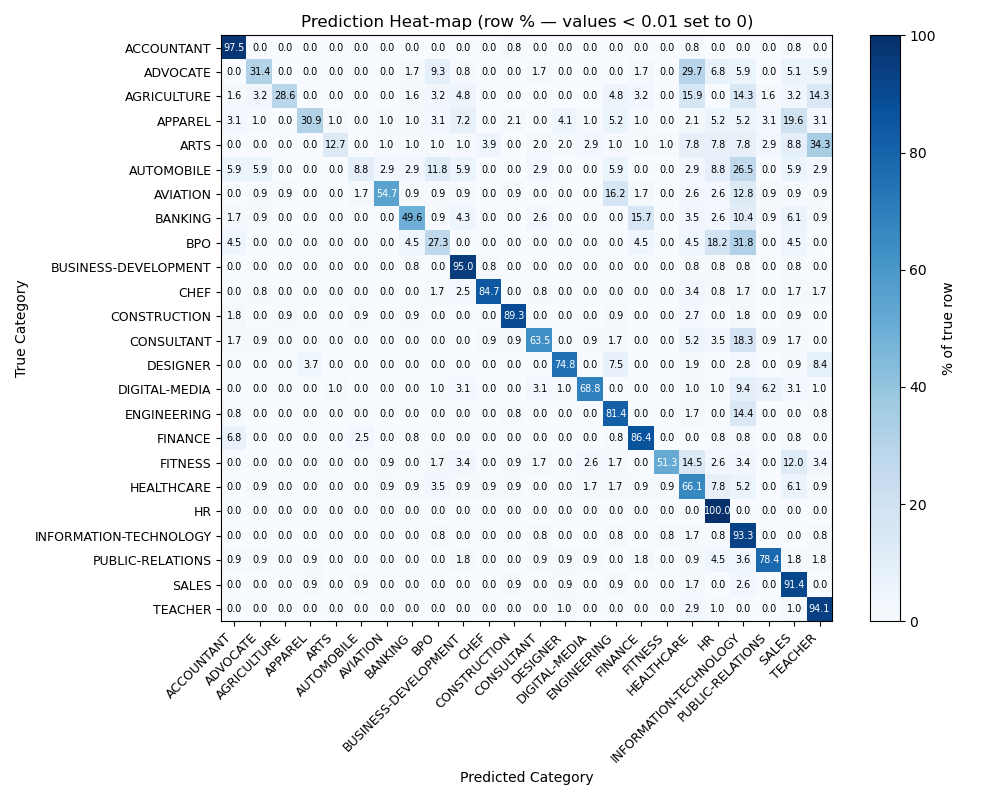
The few categories that the model frequently mis-classifies all belong to industries whose resumes share overlapping similar words and role descriptions; the classifier therefore “slides” them into better-represented neighbours that reuse the same vocabulary. A prime example is BPO, whose job ads emphasise client management and revenue growth, the same phrases that dominate Business-Development resumes, so nearly half of the true BPO cases are predicted as Business-Development.
Similar term-sharing drives the smaller leaks we see between:
Banking → Finance, Arts → Designer, and Apparel → Public-Relations.
It is quite surprising to see that all the LLMs generated several predicted categories that were not included in the prompt, as shown in the table. ChatGPT-4.1 and DeepSeek-V3 demonstrated similarly better performance compared to others. However, considering the cost of running long resume data, DeepSeek-V3 stands out as a much more cost-effective option!
If we also consider fine-tuning LLMs with an additional prediction layer, it can effectively prevent the appearance of invalid predicted categories and achieve higher accuracy, with very little cost (since it runs locally — about 5 minutes of training on an RTX 3060). However, it requires labeled training data and is harder to extend to different job categories. Additionally, we are limited by the BERT model’s 512-token constraint, which means that more than half of each resume is cut off.
Result – Experience Estimation and Level Classification
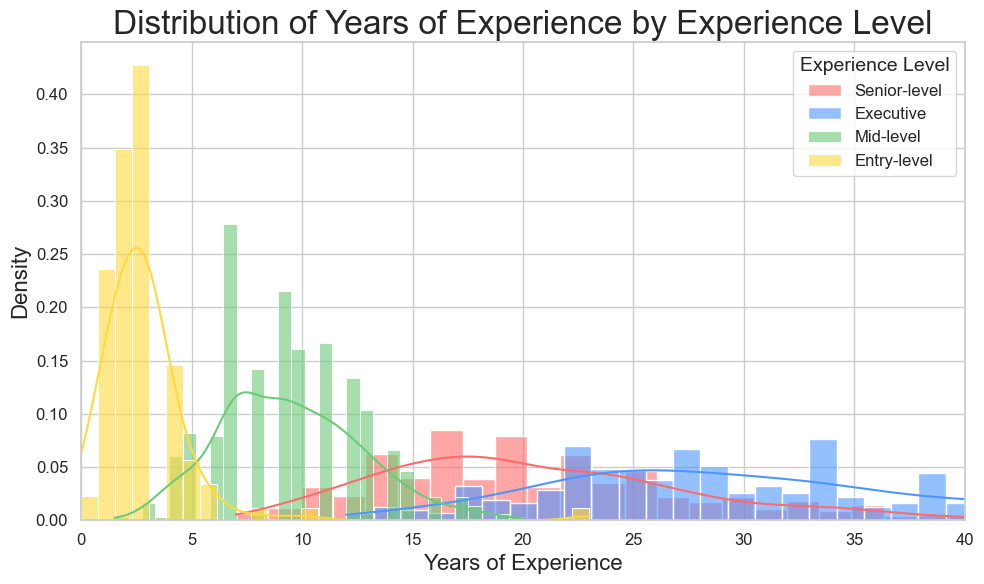
Experience Years Distribution
- Entry-level: candidates are tightly clustered between 0–5 years, showing a sharp early peak.
- Mid-level: candidates center around 5–12 years, with a broader, right-skewed distribution.
- Senior-level: professionals appear between 12–25 years, with moderate density.
- Executive-level: roles stretch across 20–40+ years, showing a flatter and wider distribution.
➔ LLM-based annotations correspond meaningfully to expected career experiences.
➔ Outliers were observed in each experience level group. This may be due to limitations of the LLM in interpreting phrases such as “to present” or “current,” where no explicit end year was provided.
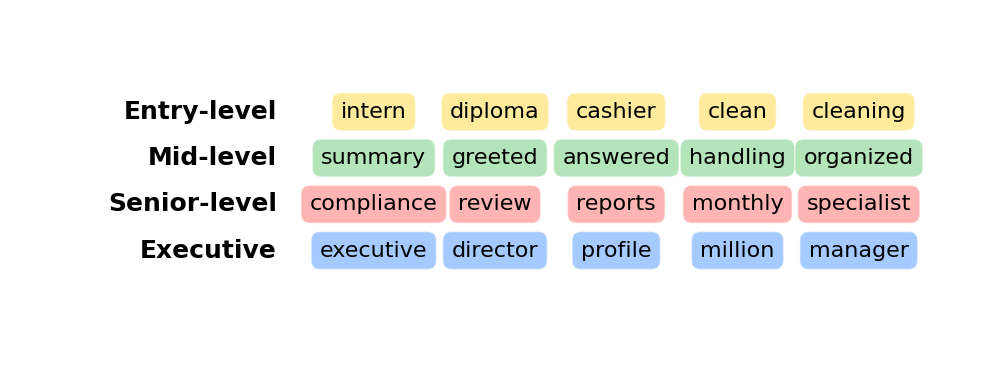
Dominant Words by Career Level
- The top words extracted for each level reflect typical responsibilities and contexts associated with that career stage:
- Entry-level: Emphasizes early roles, basic skills, and transitional positions requiring limited experience.
- Mid-level: Suggests operational duties, customer interaction, and individual contributions typical of developing professionals.
- Senior-level: Highlights management, oversight, and complex deliverables aligned with leadership positions.
- Executive: Reflects strategic leadership, financial scale, and vision-setting responsibilities.
➔ The dominant keywords offer semantic evidence that the LLM effectively captured contextual cues from the resumes, enriching the career level classification.
References
- Bhawal, S. (2021, August 8). Resume dataset. Kaggle. https://www.kaggle.com/datasets/snehaanbhawal/resume-dataset
- C. Gan, Q. Zhang, and T. Mori, “Application of LLM agents in recruitment: A novel framework for resume screening,” arXiv (Cornell University), Aug. 2024, https://arxiv.org/abs/2401.08315.
- S. S. Helli, S. Tanberk, and S. N. Cavsak, “Resume information extraction via Post-OCR text processing,” arXiv (Cornell University), Jan. 2023, doi: 10.48550/arxiv.2306.13775.
Acknowledgements
We would like to sincerely thank our sponsor Valerie Carey, Professor Caliskan, Professor Anand, and the Georgen Institute for Data Science & AI for their support and guidance throughout this project.

