Team
Jack Yu
Mentors
Michael L. Scott and Sandhya Dwarkadas
Abstract
This project implements a buffered variant of the Pronto framework used for developing persistent data structures. By relaxing the persistence requirement and processing operations in NVM in bulk, Buffered Pronto is able to achieve 1.2x to 6.7x performance increase while limiting data loss within 1 ms.
Background Information
Non-Volatile Memory (NVM)
NVM is a type of computer memory that does not lose data on power loss. Data structures that use NVM can persist their state on a crash without having to write data to disk.
Pronto
Pronto is a framework that simplifies designing persistent data structures. It provides a way to convert volatile data structures into persistent data structures by annotating which operations modify data.
Motivation
Pronto has the following limitations:
- Ensuring data structures are always consistent is slow
- Requires 2x number of processors to perform maintenance tasks quickly
- All processors contend access on small set of metadata
Buffered Pronto aims to solve this by only persisting periodically in bulk.
Buffered Pronto Features
My implementation of Buffered Pronto features the following:
- Simplified singular fast pace maintenance thread
- Reduced access to shared metadata
- Drop-in replacement for original Pronto
- thread_sync() function to flush the buffer and sync all data immediately
Performance Evaluation
I compared Buffered Pronto to two variants of the original Pronto system and Montage, a general purpose buffered persistent data structure framework developed here at the University of Rochester.
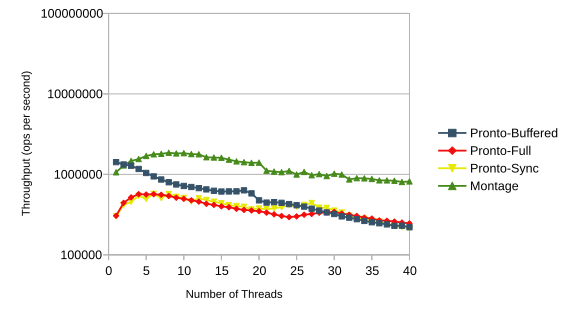
On a single socket, Buffered Pronto outperforms both variants of Pronto in throughput offering a performance increase of x1.2 to x6.7 depending on the number of threads. While Montage is significantly faster, Pronto annotations is easier to use compared to Montage’s payload-based user library.
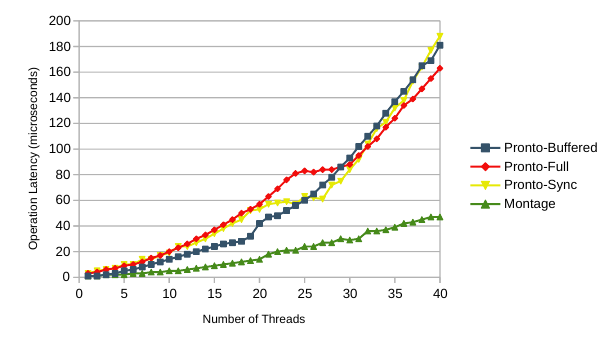
The main reason that Montage outperforms Pronto is that Montage writes data once to NVM, while Pronto needs to write it at least twice. This results in increased operation latency despite Pronto being generally faster during explicit sync() operations.
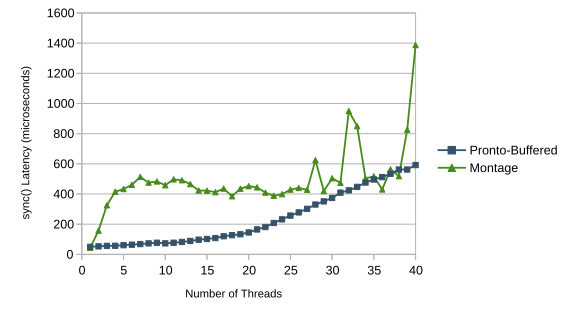
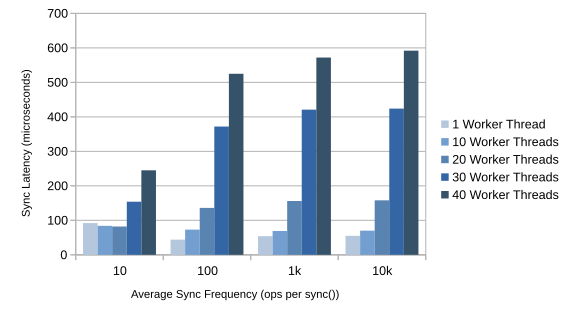
Pronto’s thread_sync() performs best when called around once per 100 to 1000 operations. thread_sync() latency increases greatly when remote memory access on another socket is involved.
The sync latency never increases past 650μs. Suggesting that regardless of whether thread_sync() is called, data loss is always contained within that time interval.
Conclusion
Buffered Pronto offers the following over the original Pronto:
- Higher throughput with low operation latency
- Fewer processors needed for maintenance tasks
- Fully compatible with existing Pronto code
The cost of using Buffered Pronto is that data persistence within 1ms is not guaranteed, which should still be acceptable for most applications.
Acknowledgements
I would like to thank Dr. Michael Scott for his contribution to buffered durable linearizability and guidance on implementing a buffered version of the Pronto system. I would also like to thank Wentao Cai and Haosen Wen for their assistance in fixing issues with the original Pronto code and for introducing me to the Montage API.