Team
Madhav Reddy Kunduru
Namitha Vanama
Nicholas Ndahiro
Mentor
Cantay Caliskan
Sponsor
City of Rochester:
Katherine May
Alyssa Montgomery
Abstract
This project aims to build a model which detects features such as crosswalks and curb ramps at intersections in the city of Rochester.
Business Understanding
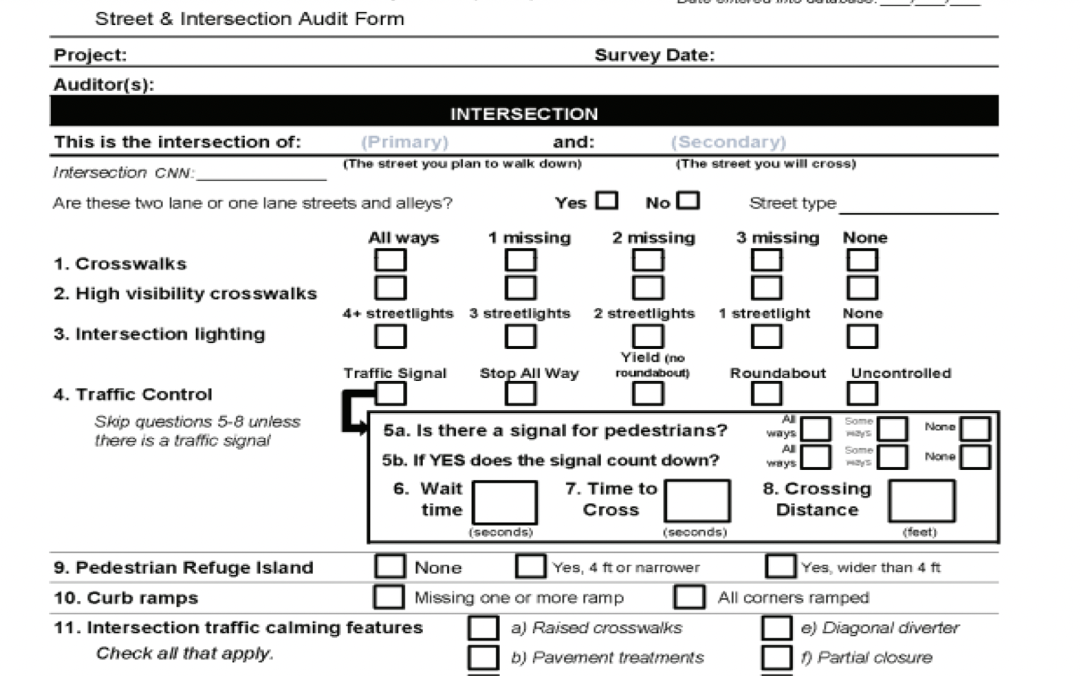
The city of Rochester would like to develop a complete inventory of pedestrian facilities and perform an assessment to identify pedestrian issues as they relate to intersection safety, traffic, street design, and perceptions of safety and walkability.
One model to consider is the Pedestrian Environmental Quality Index (PEQI) developed by the San Francisco Department of Public Health.
Goals
Analyze images of road intersections and detect specific features such as cross-walks and curb ramps assessed as part of Pedestrian Environmental Quality Index (PEQI).
Literature Review
Brief background: The PEQI (Pedestrian Environmental Quality Index) is a quantitative observational tool developed in 2008 by the San Francisco Department of Public Health to identify pedestrian issues and assess overall quality of the pedestrian environment.
City of Austin’s Planning and Development Review Department adapted and tested the PEQI tool in areas of the city that have a significant pedestrian flow to increase walkability of areas.
Distinction from our work is the use of street view versus aerial view and collection of data, the city of Austin collected data manually.

Data Description
Our Dataset has a total of 4062 images. Each image is an aerial snapshot of intersections in the city of Rochester.

Desired Output
Our desired output is to find how many curb ramps and crosswalks are missing.
Data Cleaning
Dropped 438 images which are not typically an intersection, y – junctions and over bridges.
Image Annotations
Used a tool called MakeSense.Ai to annotate/label images.
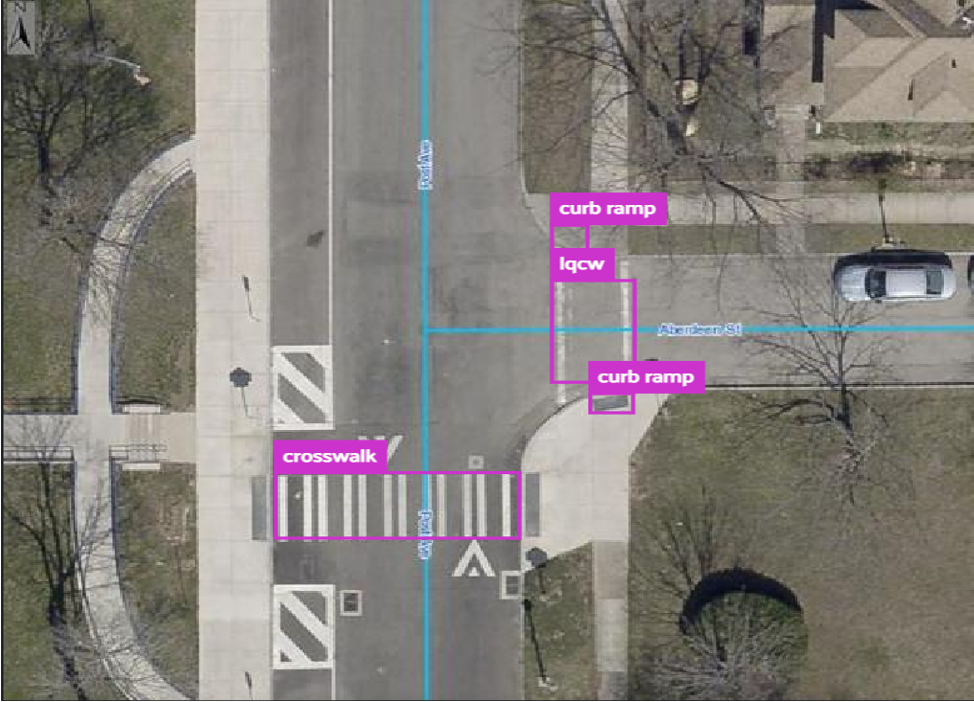
lqcw refers to low-quality crosswalk.
Exploratory Data Analysis
Typically, we have two types of intersections: T-junction and Crossroad. The optimal number of crosswalks at a crossroad is 4 whereas it is 3 at a T-junction. The optimal number of curb ramps at a crossroad and T-junction is 4.
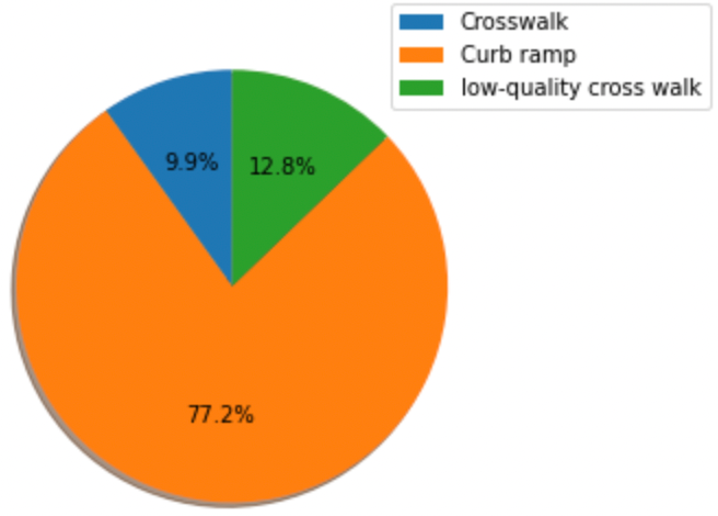
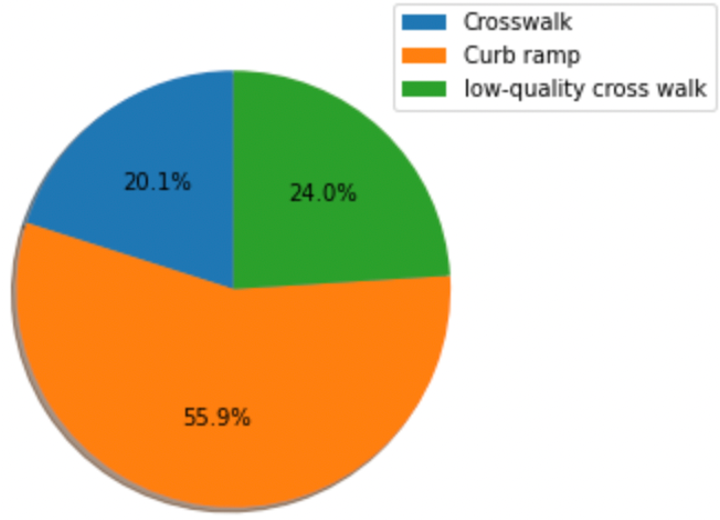
There are less crosswalks present in T-junction compared to crossroad.
Object Detection Model-YOLO
YOLO or You Only Look Once is an object detection algorithm that uses neural networks to provide real-time object detection. It is a Single-stage detector that treat object detection as a simple regression problem by taking an input image and learning the class probabilities and bounding box coordinates. It is popular because of its speed and accuracy.
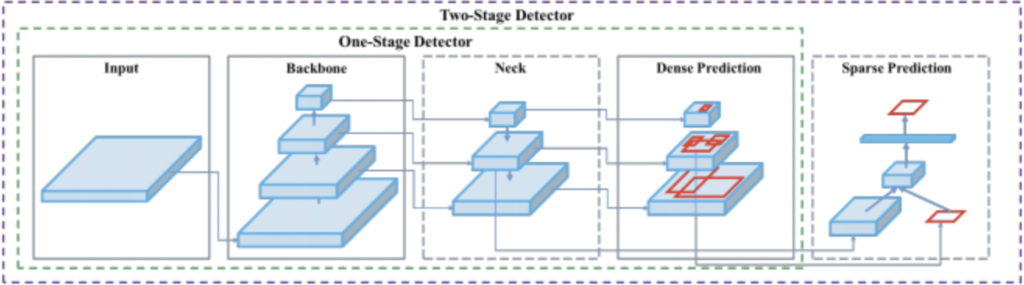
The YOLO network consists of three main pieces:
- Backbone – A convolutional neural network that aggregates and forms image features at different granularities.
- Neck – A series of layers to mix and combine image features to pass them forward to prediction.
- Head – Consumes features from the neck and takes box and class prediction steps.
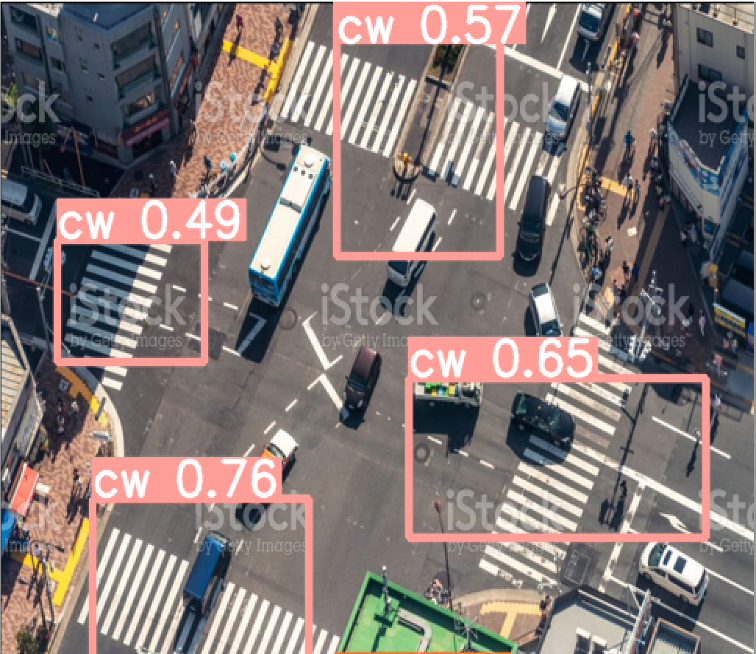
Sample Output

cw refers to crosswalk, lqcw refers to low-quality crosswalk and cr refers to curb ramp.
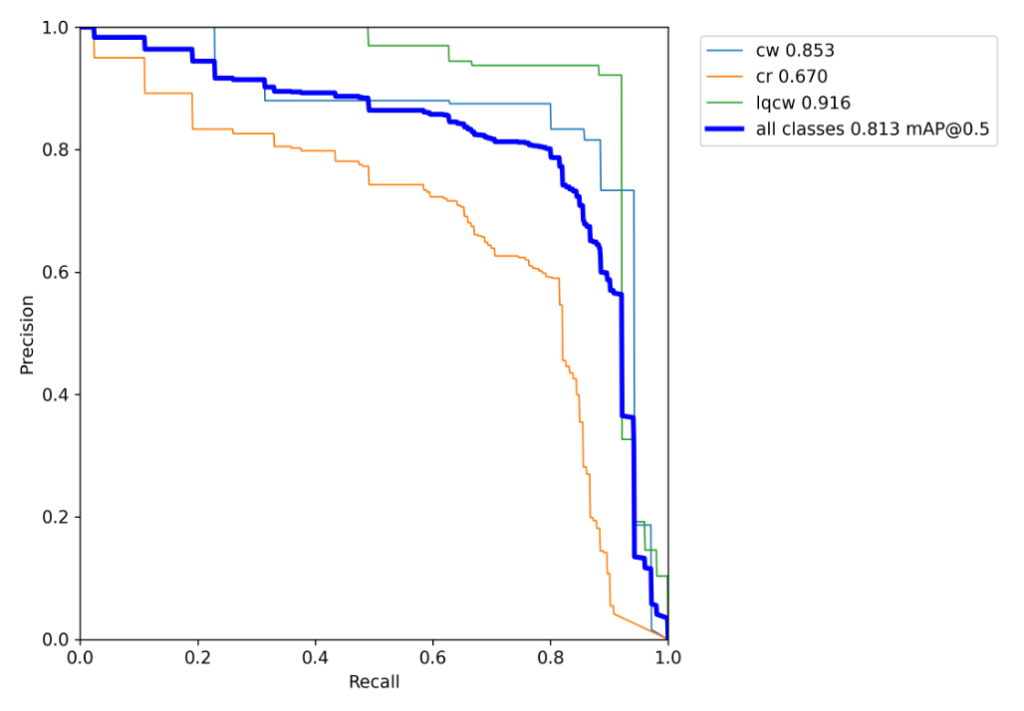
Results
The mean Average Precision of the model is 0.81. It can be observed that curb ramp is ignored as background in some cases. This is because of low quality visuals of curb ramps.
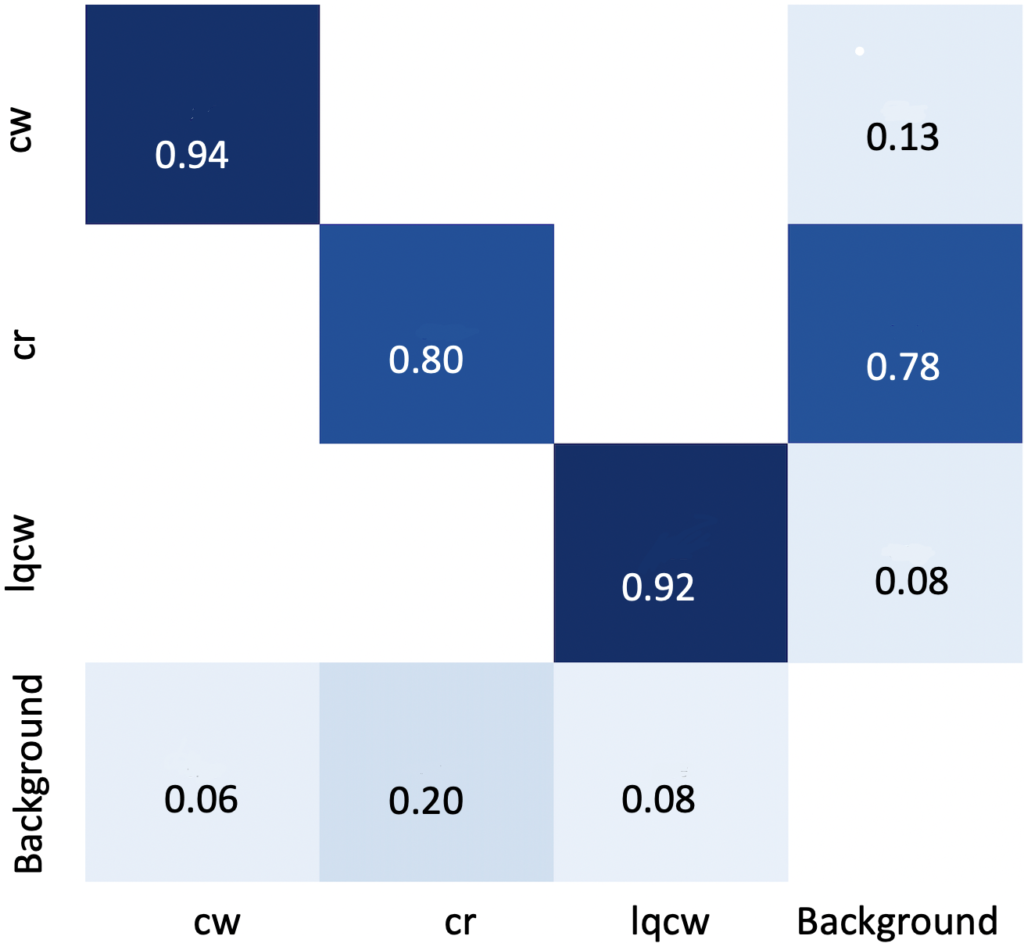
Challenges
- Quality of curb ramps in images.
- Human error while annotating images.
- Label Consistency: All instances of all classes in all images must be labelled.

Broad Application
The model is suitable to be widely used in different cities and countries.
Future Work
- Include more features as part of PEQI.
- Street view snapshots can include additional features such as street light, traffic signal, pedestrian signals.

Acknowledgements
We appreciate all the help and guidance from our sponsors Kate and Alyssa from city of Rochester and our mentor Prof. Caliskan.
References
https://blog.roboflow.com/yolov5-improvements-and-evaluation/