Team
- Tianwei Jiang
- Teghan Murray
- Sparky Shore
Mentors
Mike Heilemann, Sarah Smith, and Dan Phinney
Abstract
Imagine what a perfect midi file will sound like when all of the notes have perfect pitch, the same volume, and perfect timing. Such perfect files are usually the files that people might find online when searching for a midi file for a song. However, such a “perfect” performance is not what people prefer to hear. Music no longer has its taste if it lacks subjective interference by humans. Though it might not be a problem for professional musicians, people with trivial music knowledge might find it difficult to customize it to make it sound like a music performance. To solve the problem, a group of AME students from the University of Rochester who specialize in Audio Signal Processing, Audio Plugin Development, and Machine Learning created this senior design project.
The project’s development is around making pitch detuning, velocity variations, and time-shifting to create dequantization in real-time and non-real-time algorithms, both with and without the help of Machine Learning. In addition to that, some functions that allow the users to add “humanized” audio effects are also implemented in the plugin.
We split our project into two sections; real-time and non-real time. Running software on an entire midi file allows us to know “future” values, and thus results in an overall better or more accurate result. Running software in real-time (taking in a stream of information as it is recorded or performed) allows for more useful applications, but will not result in as good of a result.
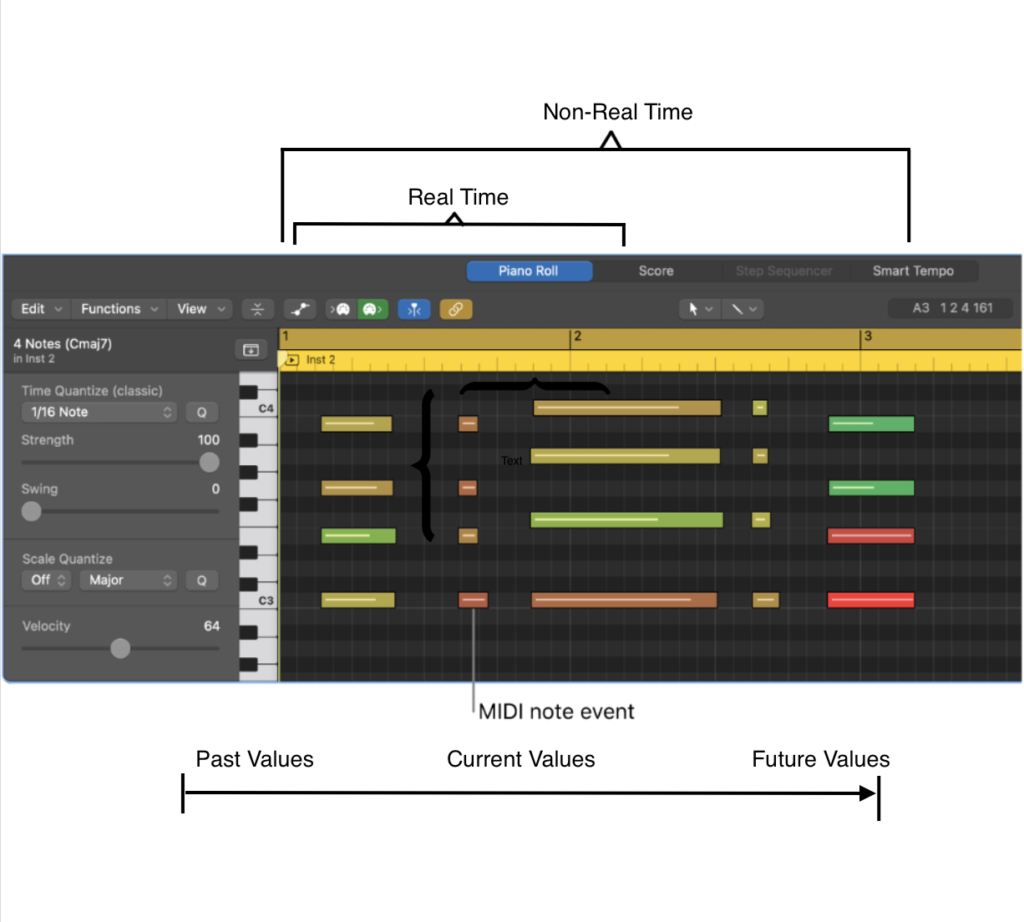
Non-Real Time
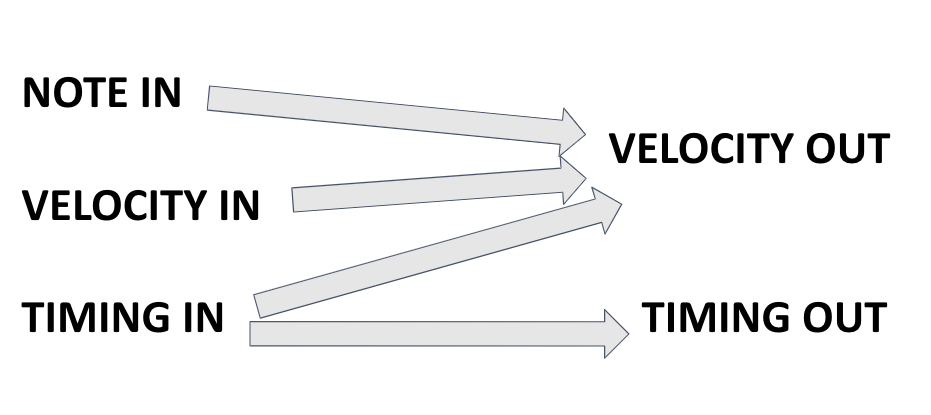
Different midi parameters have different impacts on future modifications. For example, the note value (pitch) only acts as an input, as pitch bending is required for microtonal adjustments. The timing changes are affected by just the timing between surrounding notes, but velocity (volume) is affected by note, timing, and velocity data.
After extracting different features correspond to the pitch value, velocity, and the timing, the timing shows a relatively strong correlation of 0.54 with the velocity. After removing the note off messages, the correlation is still strong around 0.25. (We select parameter correlation values >0.2 and <-0.2 as showing strong correlations, so that it can be used to train a Machine Learning model.) After the velocity and the timing are selected, a linear regression model is implemented to predict the velocity.
Non-Real-Time Algorithm
We used two Python programs, one to quantize human midi performances and one to train and test machine learning models. The quantized data was split into overlapping blocks of ten messages, which would then be fed into the machine learning models.
The machine learning program makes predictions on each block of ten messages, resulting in ten values at each position. the humanized data is the average of ten predictions at each position. In order to make the same number of predictions for every message, each midi file is padded on both ends with [0, 0, 0] messages.

Real-Time Audio Effects
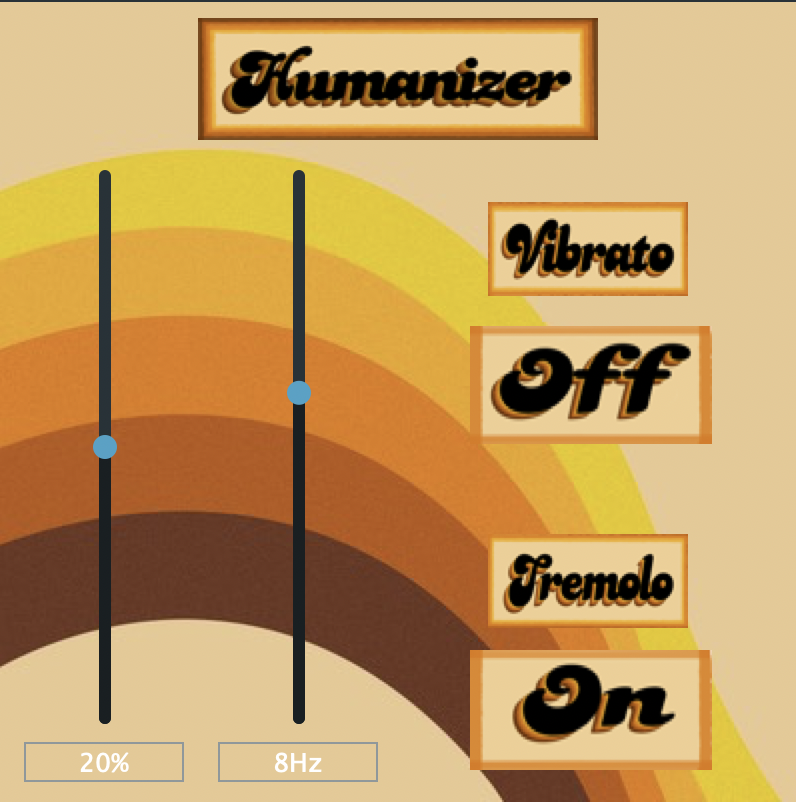
The audio section of the plugin aims to mimic authentic performances of the actual instruments. Vibrato and tremolo are the most common effect for string and brass instruments. In the real-time audio section, these two effects are implemented for the plugin. A vibrato effect is a modulation in frequency, while a tremolo effect is a modulation in amplitude. The vibrato and tremolo are both set to the best delay time and modulation frequencies such that it has the most natural effect on the instruments. In the plugin GUI (Graphical User Interface), the mix slider ranges from 0% to 40%. This range is set based on the range of the most natural effects. Two toggle buttons are placed on the right-hand side to control whether the user wants the vibrato or the tremolo effect. The algorithm uses a ring buffer to store the audio samples, determines the delay value via the delay length and an LFO (Low-Frequency Oscillation), and extracts the audio samples based on linear interpolation.
Real-Time Midi Effects
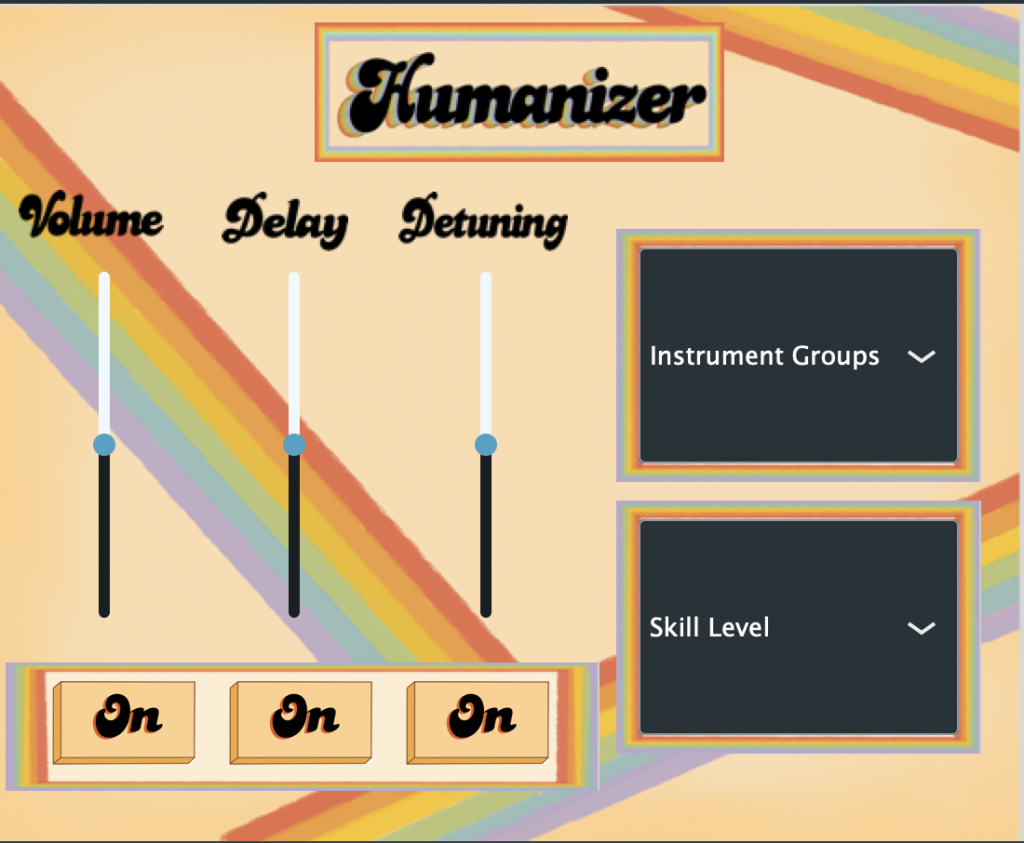
We built our plugin in JUCE, an audio plugin development platform based in C++. This plugin works in real-time, meaning we cannot use any “future” information from the midi file, only current and past information. For example, we can predict the volume of a note based on the previous note’s volume, but not the following note’s volume. The plugin uses a linear regression machine learning model to predict volume, timing, and detuning. For the “amateur” mode, the plugin uses random values to predict these parameters. Users can select different instrument groups for different algorithms. The amateur skill level will be more off-pitch and has longer delays between notes that jump in pitch. The pro skill level will correct notes that are severely out of tune, and generally has less variation in volume and timing.
Results and Comparison
The results of the non-real-time algorithm were extremely dependent on the format of the input and training data. When we trained the model to predict absolute values instead of the amount of change, the model output many extrema, to the point where entire notes would be skipped, and other notes would play together. Now, the results are subtle, but there’s more variation than the quantized file.
By using the non-real time feature correlation algorithm, velocity has a mean squared error around 4.4. The velocities are around 50-100, so the error is around 4% to 8%.
The real-time plugin uses linear regression; the pitch detuning algorithm has a RMSE value of 8.65 cents, the timing algorithm has a RMSE value of 0.072 seconds, and the velocity algorithm has a RMSE value of 9.12 (with the maximum being 127). We consider all of these values to be well within the reasonable range of values for each of these parameters, and our algorithm performs well!
Most importantly, our algorithm performs well audibly. To the well-trained ear, our plugin performs well.
Discussion
For both the real-time plugin and the non-real-time algorithm, more data from different instruments and skill levels will improve the algorithms further.
Using the non-real time correlation has only one feature used for the prediction of the velocity. In the future, more features can be added after evaluation and research. At the same time, the linear regression model suppresses the very high and low velocities. In this case, a polynomial regression model may give a better performance.
The code can also be simplified and made more readable. We could also look into building a program to handle polyphonic pieces. Currently, the code can only handle one channel.