Team
| Name | Major |
|---|---|
| Jake Brehm | Master’s in Data Science |
| Corryn Collins | Master’s in Data Science |
| Tessa Charles | Master’s in Data Science |
| Varun Arvind | Master’s in Data Science |
Mentor
Prof. Ajay Anand, Goergen Institute for Data Science
Sponsor
Virufy, Corbin Charpentier and Nicholas Rasmussen
Introduction
Virufy is a nonprofit out of California that was founded in March 2020. Originally, Virufy was focused on diagnosing COVID; now, they are looking to screen for all diseases. They aim to provide more accessible and higher quality pre-screening methods for people and governments around the world, especially those in low-income countries.
In order to do this, Virufy has created machine learning models that analyze coughs in order to determine a diagnosis. Unfortunately, there aren’t many public cough datasets, and the ones that do exist include a heavy class imbalance, i.e., there is more COVID-negative data than COVID-positive.
In order to combat this class imbalance issue, the team hoped to generate synthetic coughs that closely resemble real coughs. These synthetic coughs would hopefully be valid data for training the aforementioned machine learning models.
Project Vision
- Understand and analyze the given data
- Identify patterns and relationships in the given datasets
- Generate synthetic data using WaveGAN to correct the class imbalance
- Utilize a generative adversarial network to create synthetic audio data
- Use the produced data to train future machine learning models
- Evaluate the results on one of Virufy’s pre-existing COVID-detecting models
- Perform iterations of the model
- Calculate the inception score of WaveGAN
Dataset
All data used in this project was taken from 3 public datasets, and all of the audio files are in a flac (lossless audio) format. There are also metadata files that contain information about each audio file, such as length, country, cough start and end times, and PCR result.
EDA
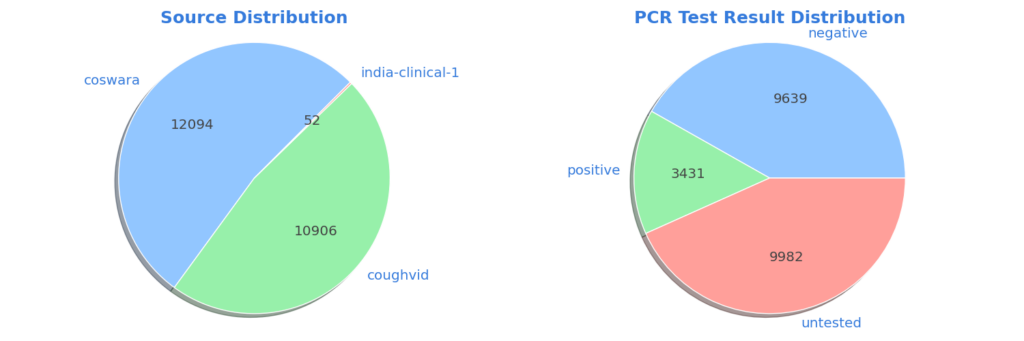
Which datasets do the audio files come from?
Virufy’s data was taken from three different sources: coswara, coughvid, and India-clinical. There was a total of 23,052 audio files used for this research, with the majority of data being from the coswara dataset. All data from each of the three data sources was utilized for training the GAN model.
What is the distribution of the PCR test results?
There is a large class imbalance present in the dataset, as a majority of the test results are COVID-negative. WaveGAN was first trained using COVID-positive and COVID-negative data, and then trained again using only COVID-positive data in order to combat this class imbalance issue.
After the coughs were recorded, the participants were administered a COVID-19 PCR test determining if they were positive or negative for the COVID virus. Above, it appears that 43.3% of the data is untested–meaning that the person was either not tested for COVID, or their test result was not recorded in the metadata. For this research, we assume that the untested results are negative for COVID. Though unlabeled, the untested data was able to provide sufficient results through inference and quality of cough sound.
What does the typical audio file look like?
| Number of audio files | 23052 audio files |
| Average audio file length | 9.34 seconds |
| Number of segmented coughs | 70316 coughs |
| Average cough length | 1.24 seconds |
| Average number of coughs per file | 3.05 coughs |
A large percentage of audio files were between 5 and 10 seconds long, as seen in the chart above. Some participants took over 20 seconds to perform their cough. This contributes to the relatively long average audio file length, which is 9.34 seconds.
The average cough is around 1.24 seconds long, which is beneficial as it is similar to the 1-second WaveGAN output length.
Out of the 23,052 audio files, there are 70,316 total coughs. In some audio files, a participant would cough multiple times; there was an average of 3.05 coughs per audio file, which further explains the considerable amount of coughs in the data.
Generative Adversarial Networks
Generative adversarial networks (GANs) are a type of deep learning model that consist of two neural networks: a generator and a discriminator.
The generator learns how to generate fake data that resembles real data, while the discriminator learns how to distinguish real data from fake data. Essentially, these two neural networks work in conjunction to create a feedback loop that drive the generator to produce more realistic data and hopefully trick the discriminator.
WaveGAN
WaveGAN, based on the original 2018 publication, is a type of GAN architecture that is designed for working directly with audio data. It is implemented in Python, takes variable-length audio files as input, and outputs 1-second audio files.
Throughout the course of this project, WaveGAN has proven to be the most successful model in the team’s attempts to generate synthetic audio data. More specifically, the team used a PyTorch implementation found on GitHub as the foundation for the model[2].
Unfortunately, WaveGAN does not classify its output, so the data generated using this model is neither meant to be COVID-positive nor COVID-negative. However, the team hoped to rectify this issue by training the model using only positive data.
Training Parameters
Two different models were run using the following parameters. One model was trained using COVID-positive and COVID-negative data, and the other was trained using only COVID-positive data. The latter model was meant to make headway into mitigating the class imbalance problem in Virufy’s data.
Using a training size of 1000 files for the positive and negative data, and 950 files for the positive data, WaveGAN took over 5 days to complete its training each time. This exemplifies that the model is not quick to train, and if the team ultimately decided to use the full training set, it would take a large amount of time and computational power.
| Training set size (positive & negative) | 1000 files |
| Training set size (only positive) | 950 files |
| Number of epochs | 180 epochs |
| Files generated per epoch | 1000 files |
Results
The following audio files are examples of the output of the team’s first WaveGAN model (that was trained on both COVID-negative and COVID-positive data) from two intermediate epochs and the final epoch. A version of the final result with added background noise in order to make it sound more similar to the average training data is included as well. This is meant to show the evolution of the model’s output over the training process.
Intermediate result (epoch 60)
Intermediate result (epoch 120)
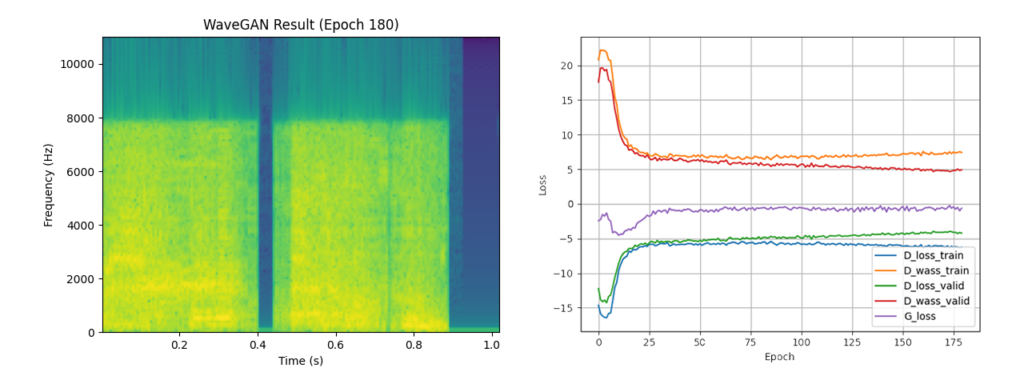
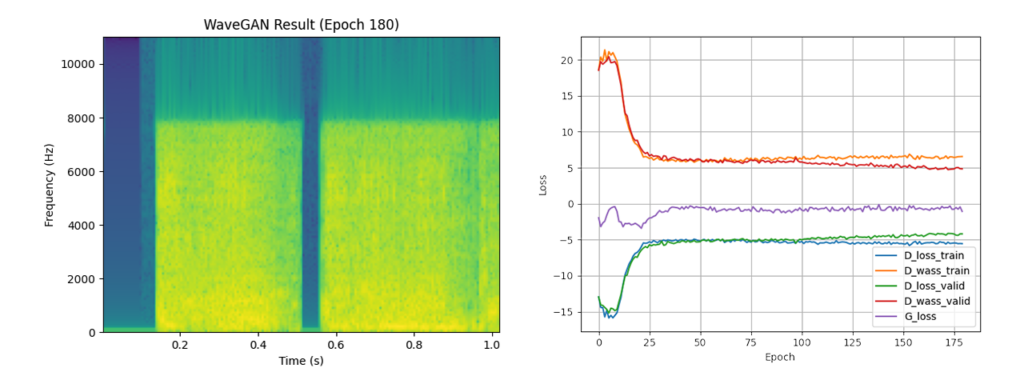
Final result (epoch 180)
Final result with background noise
The loss curve, as well as a spectrogram of a randomly selected output file generated in the final epoch, for each model is shown below. The loss curves show that the models converge after approximately epoch 15; after this point, improvement still occurs but begins to slow down quite drastically.
Evaluation
The team’s models were evaluated using inception score–specifically, a PyTorch implementation found on GitHub[3]. This score demonstrates that the models are able to produce output that is similar in diversity and quality to the training data. The results of the inception scores are seen below. Typically, a high inception score is desired.
| Description | Inception Score |
|---|---|
| Real data (original publication) | 8.01 ± 0.24 |
| WaveGAN (original publication) | 4.12 ± 0.03 |
| Real data (positive & negative) | 5.75 ± 1.15 |
| WaveGAN (positive & negative) | 4.49 ± 0.55 |
| Real data (only positive) | 5.43 ± 0.79 |
| WaveGAN (only positive) | 3.96 ± 0.59 |
In the original publication, the authors calculated the inception score on real data and got 8.01 ± 0.24, while the inception score for their WaveGAN-generated data was 4.12 ± 0.03. This is not necessarily relevant to this project, but it is a useful metric to use for comparison.
The first training set, trained on positive and negative data, scored a relatively low value of 5.75 ± 1.15, meaning there was a lot of variation in the quality and diversity of the training data. The WaveGAN-generated data scored 4.49 ± 0.55.
The second model, trained using only positive data, had similar results to the model that was trained using positive and negative data. The training data scored 5.43 ± 0.79, and the WaveGAN-generated data scored 3.96 ± 0.59. These scores were slightly lower than the scores of the first model, but this is most likely due to the drawbacks of randomly selecting training data from the full pool of available coughs, potentially allowing for undesirable data to enter the training set.
Both WaveGAN-generated inception scores are very close to their respective training data inception scores, so the team was able to infer that WaveGAN was quite successful in generating realistic data despite the small training set.
In the future, if the model is trained with 100% of the available data, one could imagine that the resulting output might sound nearly indistinguishable from real coughs.
Conclusion
WaveGAN is able to adequately generate new coughs which are comparable to the real data. The performance of both models was similar to the original publication’s, and therefore, proves to be a useful generative architecture. The model could be improved in the future by changing it to a conditional GAN architecture, which would ultimately allow for the model to classify its output as positive or negative. However, for Virufy’s purposes, the current model is a strong step towards solving the public data’s class imbalance.
Acknowledgements
The team would like to thank their sponsors from Virufy, Corbin Charpentier and Nicholas Rasmussen, for their time, guidance, and expertise. The team would also like to thank Professor Ajay Anand for his advice and instruction.
References
[1] Donahue, Chris, Julian McAuley, and Miller Puckette. “Adversarial audio synthesis.” (2018).[2] Ke Fang, WaveGAN Pytorch , (2020), GitHub repository, https://github.com/mazzzystar/WaveGAN-pytorch
[3] Shane Barratt, Inception Score Pytorch, (2017), GitHub repository, https://github.com/sbarratt/inception-score-pytorch