
Project Title: An AI-Powered Regulatory Chatbot for Labor Legislation
Team Members: Ethan Leung, Carol Li, Astha Singh, Keming Zhang
Sponsor: Paychex
Affiliation: Goergen Institute for Data Science, University of Rochester
INTRODUCTION
In today’s fast-evolving regulatory landscape, businesses must constantly adapt to changes in federal and state legislation to ensure compliance in areas such as payroll, taxation, and human resources. Paychex, a leading provider of integrated HR solutions, faces the challenge of maintaining up-to-date regulatory information to effectively support over 740,000 clients. This capstone project focused on an AI-powered chatbot designed to assist Paychex in delivering accurate and timely regulatory guidance.

https://news.cornell.edu/stories/2024/07/research-decision-making-mystery-ai-chatbots
OBJECTIVES
Our work culminates in a scalable, automated system that improves access to complex legal information, supporting efficient and dependable client service. By combining advanced AI methods with robust data management, the system aims to provide Paychex with reliable, up-to-date information, which enhances operational efficiency and ensures adherence to complex regulatory requirements.
- Analyze and prepare data for model integration
- Build and optimize the vector database
- Develop the retrieval-augmented generation agent graph
- Integrate the chatbot with data and graph functions
DATA DESCRIPTION
The original dataset comprises regulatory information related to labor laws at both the federal and state levels. The dataset initially contained 1,124 entries, with each row representing a distinct regulation, accompanied by a brief description and a hyperlink to the official source. One entry was removed due to a missing URL, resulting in a final dataset of 1,123 complete records for analysis.
There are three types of data sources—Web Resource, PDF, and HTML—each scraped using distinct techniques. A total of 1036 links were successfully scraped, while 87 errors remain. All extracted text was compiled into the dataset.
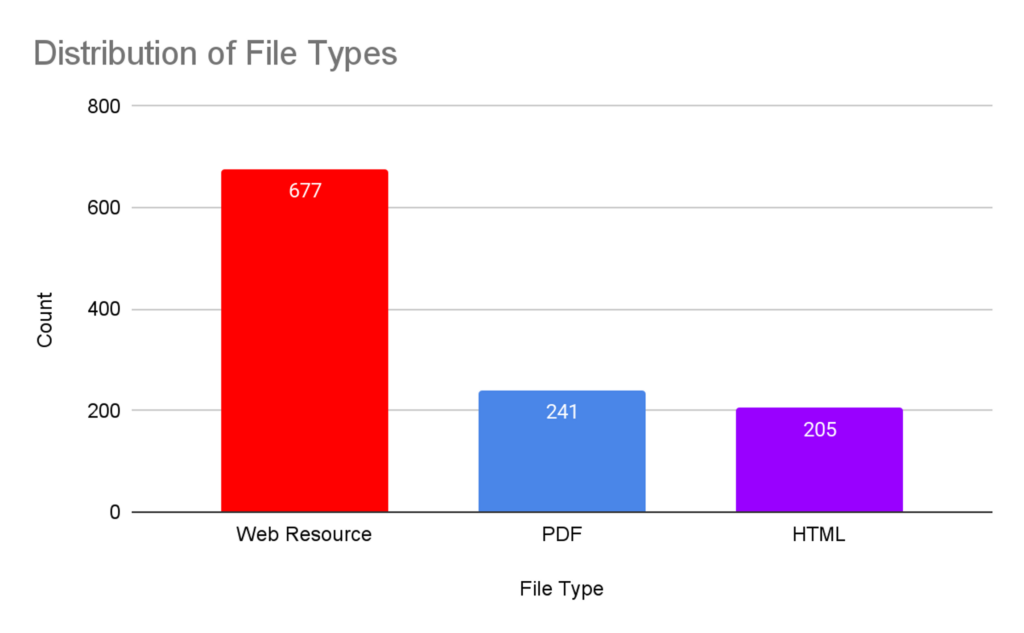
Figure 1: Distribution of File Types
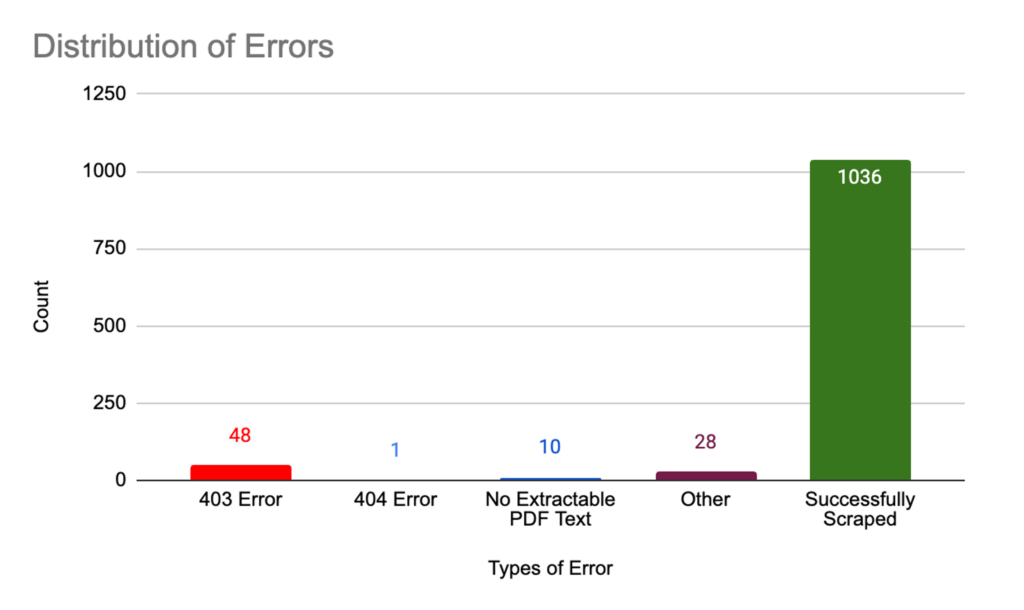
Figure 2: Distribution of Errors
METHODS
Feature Engineering
Procedure based on the Description column:
- Added “Category” column based on keywords in the description: paid_sick_leave, childcare_regulations, wage_minimum_industry, holiday_pay_provisions,work_hour_regulations, employment_statutes, fair_labor_standards,employee_leave_benefits.
- Added a Jurisdiction column to categorize each row as either Federal or State.
- Added State and State Code columns to classify all State-level regulations according to the 50 U.S. states.
Among the eight categorized themes, paid_sick_leave accounts for the highest number of regulations (255), followed by childcare_regulations (238) and wage_minimum_industry (216). In contrast, categories such as fair_labor_standards (64) and employee_leave_benefits (44) are represented less frequently. This distribution highlights the relative prominence of certain labor regulation themes, particularly those related to paid leave and childcare, within the dataset.
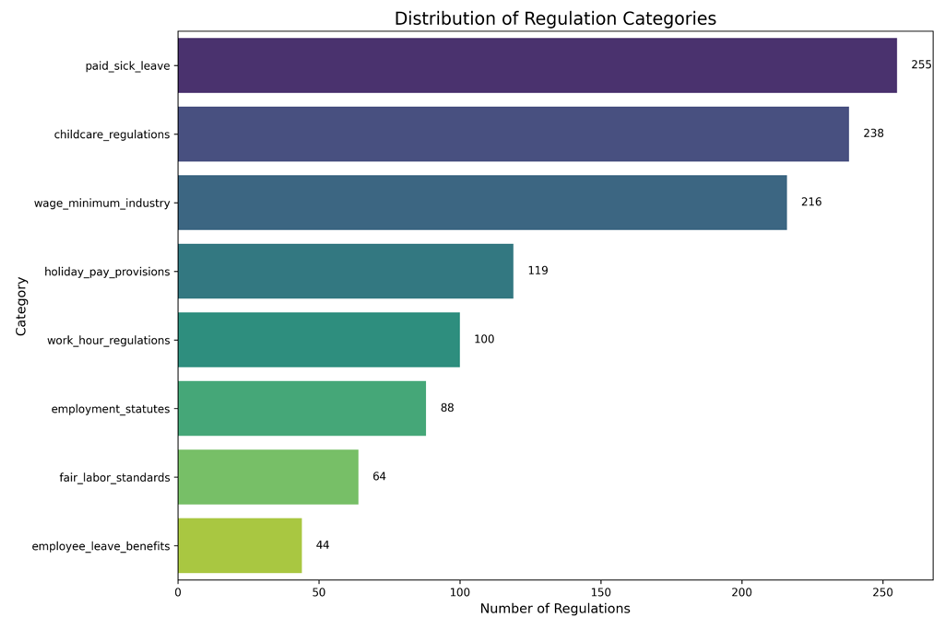
Figure 3: Distribution of Regulation Categories
Another feature added during the engineering process was the Jurisdiction column, which classifies each regulation as either Federal or State in scope. A figure was created to show the distribution of Jurisdiction. We can observe that there are 911 state-related regulations and 212 federal-level regulations. The number of state regulations is highly outweighs the number of federal laws.
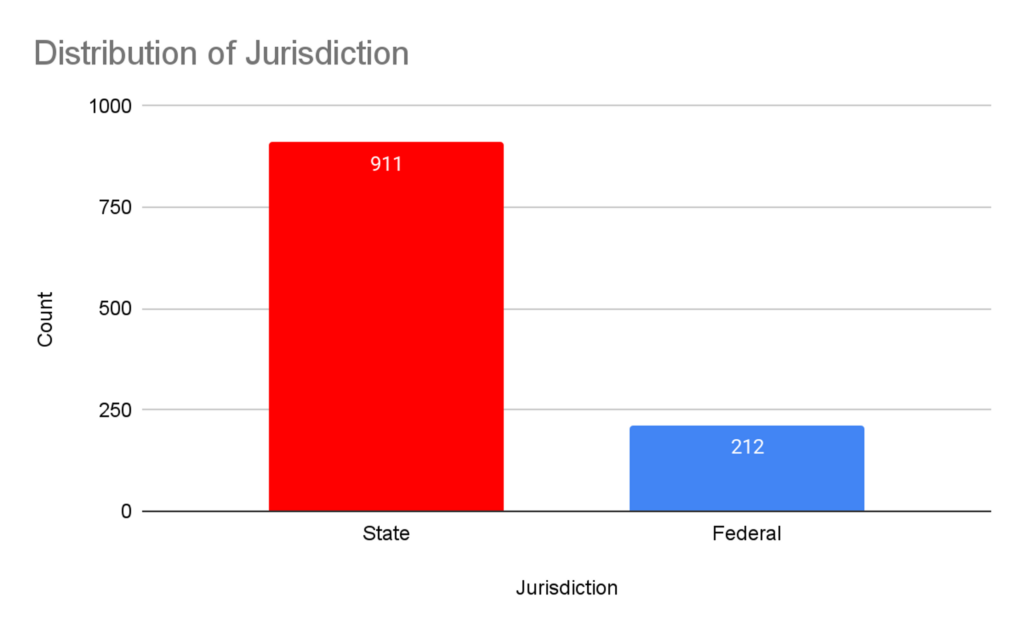
Figure 4: Distribution of Jurisdiction
Furthermore, two supporting columns—State and State Code—were introduced to facilitate the classification of all state-level regulations according to the 50 U.S. states. Analysis of these columns reveals that the majority of state regulations in the dataset originate from a subset of states, including Maryland (MD), Minnesota (MN), New York (NY), California (CA), Montana (MT), Arizona (AZ), New Jersey (NJ), Massachusetts (MA), New Mexico (NM), and Maine (ME). This distribution may reflect differences in regulatory activity or data availability across states.
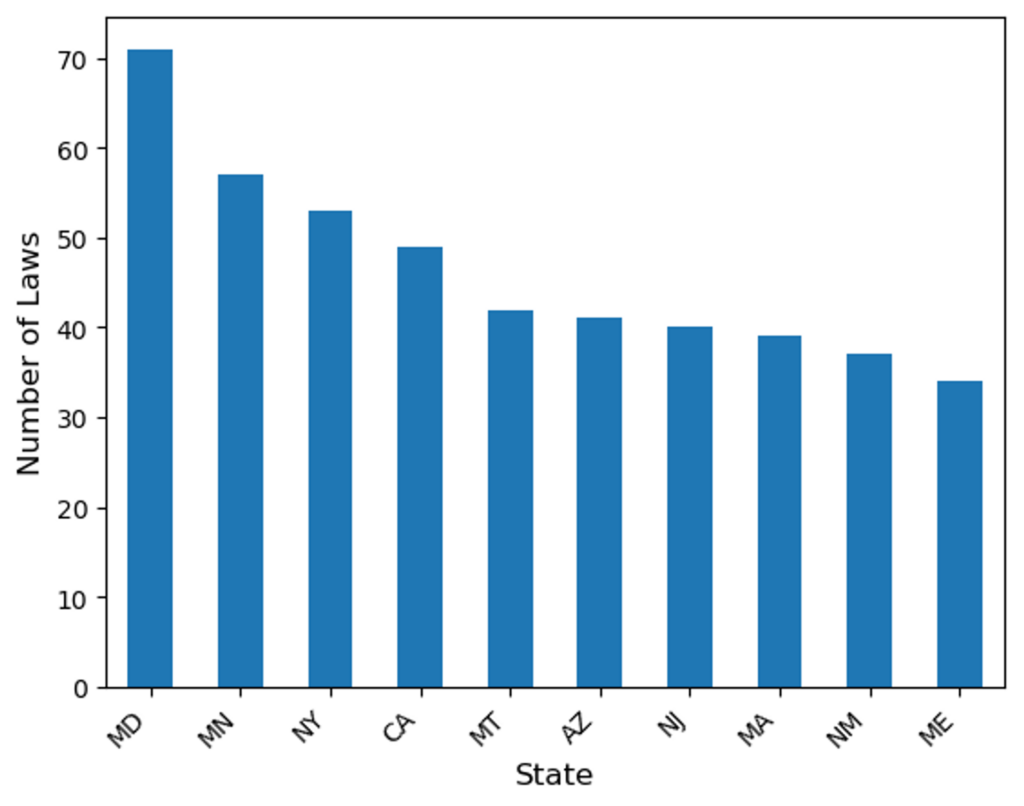
Figure 5: Distribution of Number of Laws by State
FAISS Vector Database
A brief steps as follows:
- Database 2. Embedding 3. FAISS Index 4. Indexing 5. TF-IDF 6. Searching
We used FAISS (Facebook AI Similarity Search) to build a fast, efficient search system that matches user queries to relevant labor laws. By converting legal text into vector embeddings using models like BERT, the chatbot can quickly find semantically similar content. We also incorporated TF-IDF scoring to enhance result accuracy and relevance.
Hybrid Search
To improve precision, we combined semantic vector search with traditional keyword matching in a hybrid approach. This ensures that the chatbot not only understands the meaning behind a query but also captures important legal terms. By ranking results based on both methods, the chatbot delivers more relevant and legally accurate answers.
LangGraph
We used LangGraph to manage the chatbot’s multi-step reasoning, including searching, filtering, and generating responses. This structure allows the system to fall back on a controlled Google Search if no internal data matches a query, ensuring reliability. Prompts guide each AI agent’s role, enabling smooth and accurate interactions.
RESULTS
The project resulted in the creation of three models that improved upon each other. The workflow of the chatbot is pictured below, along with a model comparison of each model’s performance in a few common scenarios. Observably, the first version was the fastest but gave too succinct responses. The second sacrificed speed for answer quality, but fell short in hyper-specific queries. The final sees the same speed decrease, but it works well in all scenarios.
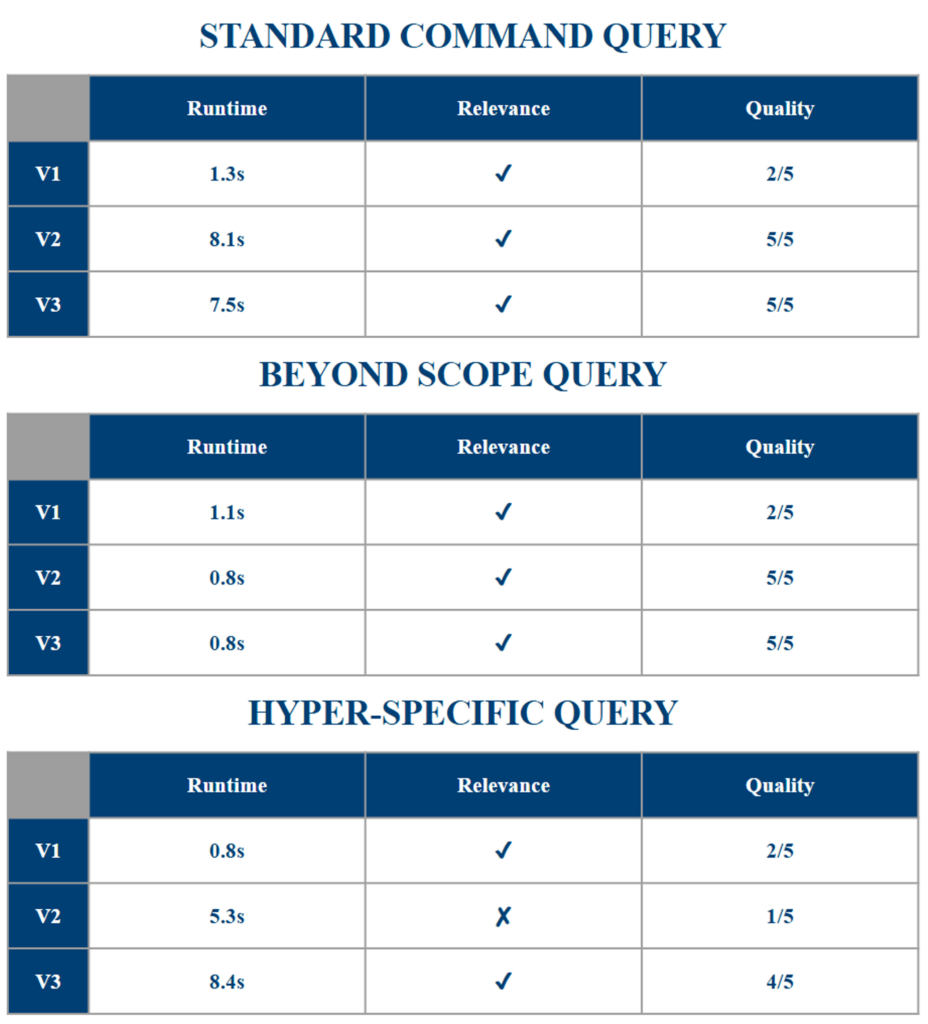
Figure 6: Model Comparison of Each Model’s Performance
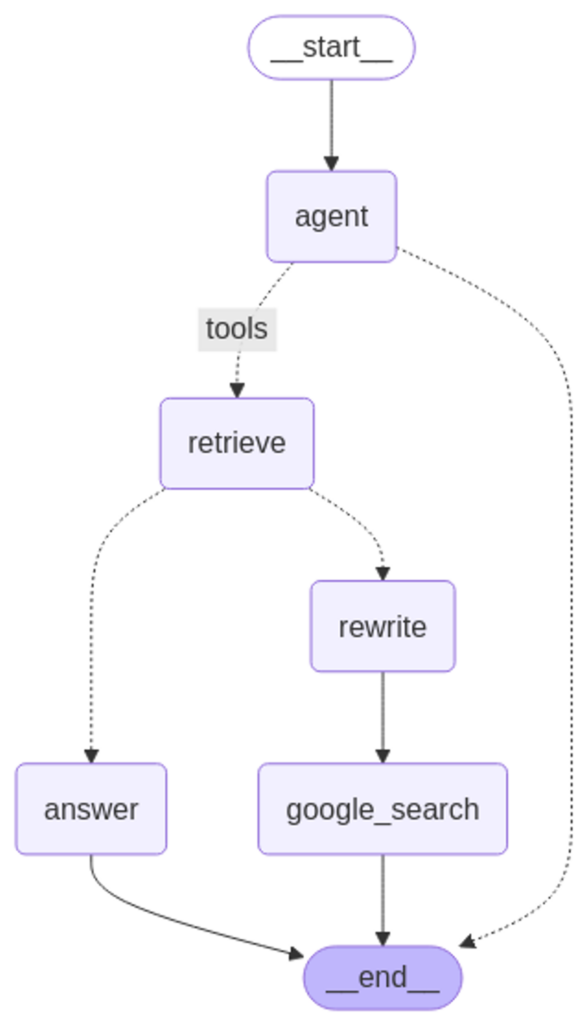
Figure 7: LangGraph Workflow Version 3
DEMO
CONCLUSION & NEXT STEPS
As a whole, the project opens avenues of usage for similar use cases in other fields to create specialized chatbots to aid in specific research. A major area of improvement for a project like this could be to refine the Google Search fallback to be used more prominently, as it would reduce the need to manage the initial knowledge base.
ACKNOWLEDGEMENT
We would like to thank Professors Anand and Caliskan for their continuous support and mentorship, as well as Ledion Lico, Daniel Riggi, Ravi Dugh, Michelle Li, Lilly Xie, and Jing Zhu at Paychex for their guidance throughout the project.
REFERENCES
1.What is Rag? – retrieval-augmented generation AI explained – AWS. (n.d.). https://aws.amazon.com/what-is/retrieval-augmented-generation/
2.Roller, J. (2024, May 15). Understanding vector databases: The foundation of modern AI applications. IEEE Computer Society. https://www.computer.org/publications/tech-news/community-voices/vector-databases-and-ai-applications/
3.Web scraping: Jurisprudence and legal doctrines – fontana – 2025 – the journal of world intellectual property – wiley online library. (n.d.-a). https://onlinelibrary.wiley.com/doi/10.1111/jwip.12331?af=R
4.Vine, J. (n.d.). pdfplumber [Computer software]. GitHub. https://github.com/jsvine/pdfplumber
5.Richardson, L. (2007). Beautiful Soup Documentation. Crummy.com. https://www.crummy.com/software/BeautifulSoup/
6.SeleniumHQ. (n.d.). Selenium WebDriver. https://www.selenium.dev/documentation/webdriver/
7.Reitz, K. (n.d.). Requests: HTTP for Humans. Python-Requests.org. https://docs.python-requests.org/
8.Faiss | 🦜️🔗 LangChain. (2024). Langchain.com. https://python.langchain.com/docs/integrations/vectorstores/faiss/
9.Reimers, N., & Gurevych, I. (2019, August 27). Sentence-bert: Sentence embeddings using Siamese Bert-Networks. arXiv.org. https://arxiv.org/abs/1908.10084
10.Johnson, J., Douze, M., & Jégou, H. (2017, February 28). Billion-scale similarity search with gpus. arXiv.org. https://arxiv.org/abs/1702.08734?context=cs
11.Gao, L., Dai, Z., & Callan, J. (2021, April 15). Coil: Revisit exact lexical match in information retrieval with contextualized inverted list. arXiv.org. https://arxiv.org/abs/2104.07186
12.Cohorte. (2024, November 15). Unleashing the Power of LangGraph: An Introduction to the Future of AI Workflows. Cohorte.co; Cohorte. https://www.cohorte.co/blog/unleashing-the-power-of-langgraph-an-introduction-to-the-future-of-ai-workflows