Team
Mehmed Emre Aktaş, Navya Bhagat, Lakshmi Kanumuri, Narm Nathan
Sponsor: Dr. Erika Ramsdale, University of Rochester Medical Center
Instructor: Dr. Cantay Caliskan, University of Rochester Goergen Institute for Data Science and Artificial Intelligence
Background
Chemotherapy decisional regret is a common yet often overlooked emotional outcome among older adults undergoing cancer treatment. Patients who regret their treatment choices frequently report reduced quality of life, heightened psychological distress, and damaged trust in the healthcare process1,2,3.
Despite the clinical significance of decisional regret, oncology care currently lacks widely adopted predictive tools that can identify high-risk patients before treatment begins. As a result, many older adults face irreversible emotional consequences due to uninformed or misaligned decisions, revealing a critical gap in the shared decision-making process2.
By proactively identifying individuals who may be susceptible to regret, clinicians have the opportunity to engage patients in more transparent, supportive, and personalized conversations about their treatment options.
Objective
The goal of this project is to develop a clinically interpretable machine learning model capable of predicting chemotherapy decisional regret in older cancer patients using structured clinical and functional data collected at baseline—before treatment is initiated.
This tool is intended to support real-time clinical decision-making by enabling early identification of patients at risk for emotional harm, ultimately fostering higher-quality, values-aligned cancer care.
Data & Cohort
This study leveraged data from the Geriatric Assessment in Oncology (GAP) dataset, a comprehensive multicenter repository designed to evaluate the health, treatment experiences, and outcomes of older adults with cancer.
Cohort Overview
- Sample Size: 718 Patients
- Inclusion Criteria: Adults aged 75 years or older undergoing cancer treatment
- Recruitment Sites:
- Wilmot Cancer Institute
- Highland Hospital
- Both institutions are affiliated with the University of Rochester Medical Center and specialize in the care of older oncology patients.
Data Collected
The dataset includes over 300 structured variables, grouped into the following domains:
- Demographics: Age, sex, race, marital status, insurance type
- Cancer Characteristics: Diagnosis type, cancer stage, treatment modality (e.g., chemotherapy, radiation, hormonal therapy)
- Geriatric Assessments: Activities of Daily Living (ADLs), Instrumental ADLs, polypharmacy indicators, mobility scores, cognitive status, nutritional risk
- Symptom Burden & Toxicity: Patient-reported severity of symptoms (e.g., nausea, fatigue, skin reactions), treatment-related toxicities, and life interference scales
- Patient-Reported Regret: Decisional regret measured using a validated 0–100 scale, where higher scores reflect greater levels of regret
Clinical Relevance
This diverse and rich dataset provided the foundation for building a machine learning model that captures not only physiological risk but also emotional vulnerability—enabling more holistic patient profiling and predictive modeling.
Preprocessing & Feature Engineering
To prepare the dataset for machine learning, we implemented a robust preprocessing pipeline designed to maximize data quality, retain clinical meaning, and ensure compatibility with standard modeling frameworks.
Data Cleaning & Consolidation
- Redundant and duplicate columns were removed to reduce noise.
- Variables with over 80% missing data were excluded to preserve model integrity.
- Non-informative fields (e.g., administrative IDs, redundant flags) were filtered out to prevent overfitting.
Handling Missing Data
- Missing values were imputed using Multiple Imputation by Chained Equations (MICE).
This technique preserved the multivariate relationships between features and is widely used in healthcare modeling for its statistical rigor.
Encoding Categorical Variables
- Categorical features (e.g., cancer stage, treatment type) were label encoded to reflect ordinal structure where appropriate.
- This approach allowed us to maintain the clinical hierarchy of variables (e.g., Stage I < Stage II < Stage III).
Scaling Numerical Variables
- All continuous features were standardized using z-score normalization.
This ensured comparability across features measured on different scales (e.g., age vs. symptom scores), which is essential for distance-based algorithms and improves logistic regression stability.
Demonsionality Consideration
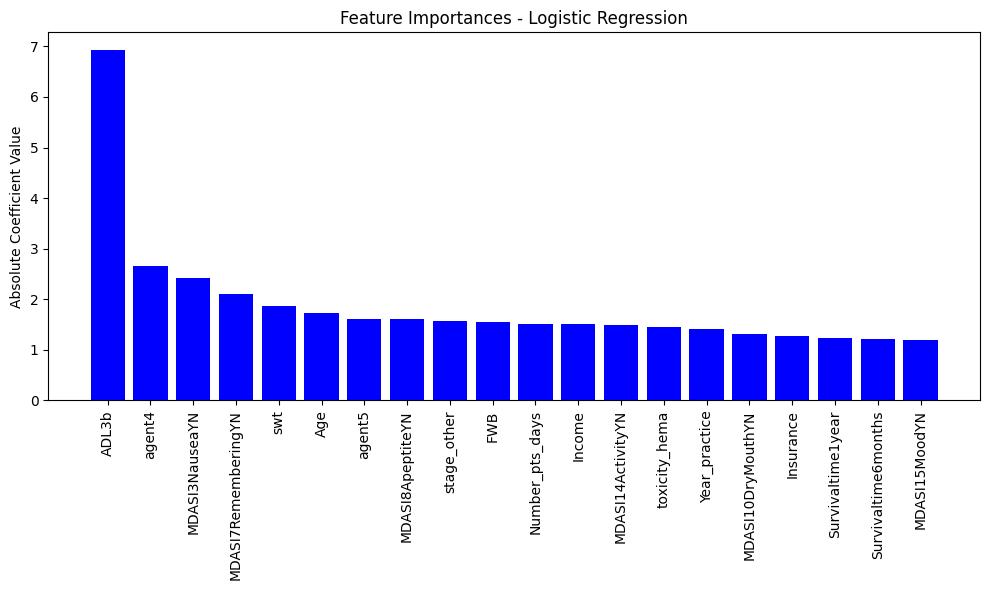
- After preprocessing, the dataset was reduced to a refined subset of 20 clinically meaningful features—selected via coefficient ranking from an initial full-feature model.
- These features formed the basis of both the final logistic regression model and the reduced model optimized for deployment.
Clinical Alignment
Throughout preprocessing, we ensured that no transformation distorted the original clinical interpretation of the data. Every feature retained in the final model remains both statistically significant and medically intuitive, preserving trust and applicability in real-world settings.
Modeling Approach
To predict chemotherapy decisional regret in older adults, we implemented a supervised learning pipeline with logistic regression as the primary model. This choice was motivated by the model’s predictive strength, interpretability, and alignment with clinical deployment standards.
Why Logistic Regression?
In a clinical context, models must not only be accurate—they must also be explainable. Logistic regression provides clear coefficients that represent the direction and magnitude of feature influence, making it a transparent and trusted tool for decision support.
Training & Evaluation Strategy
- Dataset Split: 80% training / 20% testing
- Evaluation Metrics:
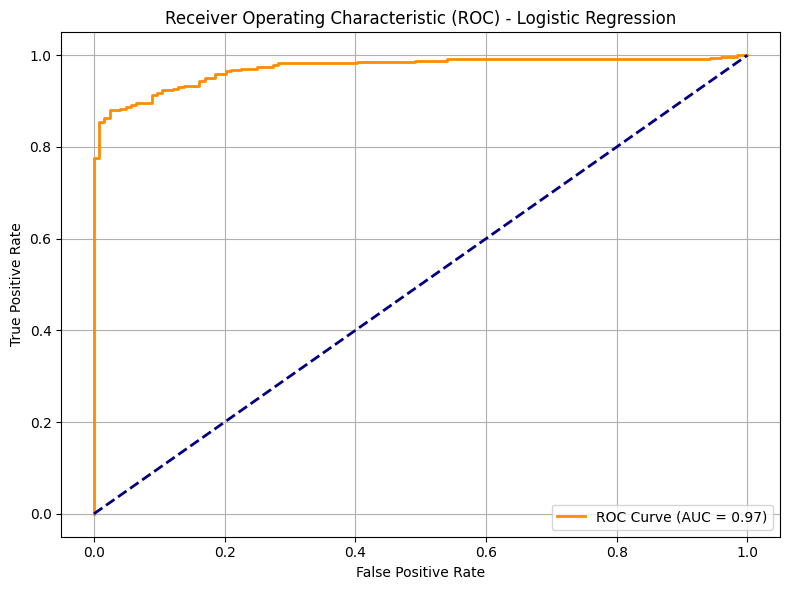
- ROC – AUC: 0.97
- Precision: 0.94
- Recall: 0.94
- F1-Score: 0.94
These results reflect the model’s strong ability to identify patients who will go on to experience high regret—without sacrificing sensitivity, a crucial requirement for proactive clinical interventions.
Top Predictive Features
| Feature | Coefficient | Interpretation |
|---|---|---|
| Ability to eat on own | −6.93 | Strongly protective against regret |
| Chemo Agent Type 4 | +2.65 | Increased likelihood of regret |
| Nausea | −2.41 | Associated with lower regret |
| Memory difficulty | +2.10 | Strongly predictive of high regret |
| Age | −1.72 | Slight protective effect in older subgroups |
Key Takeway
Logistic regression allowed us to balance performance with clarity, creating a model that not only works—but makes sense. It provides clinicians with actionable insights rooted in data and aligned with the lived realities of patient care.
Model Optimization
To balance performance with real-world usability, we optimized our model by reducing the feature set from hundreds of variables to the top 20 most predictive features, as determined by logistic regression coefficients.
Why Feature Reduction Matters?
- Clinical Efficiency: Healthcare providers benefit from tools that are quick, intuitive, and don’t require exhaustive data collection.
- Model Simplicity: Simpler models generalize better, especially when deployed across institutions with varied data quality.
- Interpretability: Each feature retained is clinically relevant and easily explainable, increasing provider trust in model outputs.
Performance Comparison
| Model Version | Number of Features | Accuracy |
|---|---|---|
| Full Feature Model | 300+ | 92% |
| Reduced Feature Model | 20 | 99% |
Clinical Takeaway
This optimization step ensures our model is not only accurate but also practical, paving the way for seamless integration into decision support systems used in real oncology settings.
Alternative Analysis
In addition to our primary binary classification model, we explored several alternative modeling strategies to examine whether more granular or dimensional approaches could yield deeper insight into regret prediction.
Multi-Class Regret Classification
Objective: Predict patient regret on a 3-level scale:
- Category 0 (Regret Score = 0): No regret
- Category 1 (Regret Score 1-25): Moderate Regret
- Category 2( Regret Score >25): High Regret
Model: Multinomial Logisitc Regression
- Accuracy: 84%
- Macro Average F1: 0.79
- Weighted Average F1: 0.83

Insight
While this model provided reasonable separation across regret levels, the added complexity did not significantly improve clinical utility over the binary model. The binary approach proved easier to interpret and act on in real-world workflows.
Principal Component Analysis (PCA)
Goal: Reduce high-dimensional feature space into thematic components
Output: 5 clinically relevant principal components
- PC1: General Symptom & Distress Load
- PC2: Physical Function & Disability
- PC3: Symptom Interference with Mobility
- PC4: Chemo Toxicity & Treatment Complications
- PC5: Neurological & Autonomic Dysfunction
Model Accuracy: Dropped to 76%
Insight
PCA captured latent themes in patient health but sacrificed predictive precision—highlighting a trade-off between dimensionality reduction and model performance.
Continuous Regret Prediction
Model Type: Linear Regression
Target: Full regret score (0-100)
Top Predictors:
| Variable | Coefficient | R² | MSE |
|---|---|---|---|
| ADL Impairment | +1.135 | 0.008 | 156.8 |
| Cognitive Impairment | +0.710 | 0.003 | 157.6 |
| Mobility Impairment | +0.547 | 0.002 | 157.8 |
| Chemo Agent 3 | +0.653 | 0.003 | 157.7 |
| Chemo Agent 4 | +0.452 | 0.001 | 157.9 |
Insight
Although regression identified clinically sensible predictors, the R² values were very low, indicating weak explanatory power. This further validated our choice of a binary classification approach.
Clinical Application: A Patient-Centered Use Case
Meet Maria
Maria is a 75-year-old woman recently diagnosed with early-stage breast cancer. During her pre-treatment intake assessment, she reports:
- Difficulty eating independently
- Ongoing memory issues
- Frequent episodes of nausea
While these symptoms might seem typical for her age and diagnosis, they are key inputs into our machine learning model.
Model Output
Maria’s responses are processed through our logistic regression model, which assigns her a risk score of 0.72—above the threshold for high risk of experiencing chemotherapy decisional regret.
Clinical Response
Because of the elevated score, her provider receives a real-time prompt:
“This patient may be at high risk of treatment regret. Consider further evaluation and counseling before proceeding with therapy.”
This triggers a shared decision-making conversation, where the provider explores Maria’s concerns, clarifies treatment goals, and presents alternative options tailored to her physical and emotional needs.
Revised Care Plan
As a result of this early intervention:
- Maria receives additional counseling to help her fully understand the trade-offs of chemotherapy
- Supportive care is initiated for her symptoms
- Her treatment plan is adjusted to align more closely with her personal preferences and functional limitations
Outcome
Maria later reflects:
“I felt heard and empowered. I’m glad I understood all my options”
Her regret is mitigated—not because chemotherapy was avoided, but because the decision-making process became truly collaborative, informed by her data and supported by predictive analytics.
Conclusion
This project illustrates the transformative potential of machine learning in advancing patient-centered oncology care. By leveraging structured clinical, demographic, and functional data collected before treatment begins, we developed a model that can proactively identify older adults at high risk for chemotherapy decisional regret—a deeply personal outcome that often goes undetected until it’s too late.
Our final logistic regression model demonstrated:
- High predictive accuracy (ROC-AUC = 0.97)
- Strong clinical alignment with meaningful features like cognitive function, therapy satisfaction, and symptom burden
- Clear interpretability, making it suitable for integration into real-world clinical workflows
In a landscape where many machine learning models act as black boxes, our approach prioritizes transparency, usability, and trust—key factors for adoption in high-stakes healthcare settings.
Ultimately, this work moves us closer to a future where data-driven tools don’t just predict outcomes—they support better conversations, more informed choices, and care that truly reflects the goals and values of every patient.
Future Directions
While our current model effectively uses structured data to predict chemotherapy decisional regret, many rich clinical insights remain hidden in unstructured formats—particularly within provider-patient conversations.
Next Phase: Language-Aware Modeling
Our next step is to integrate Large Language Models (LLMs) to process and analyze clinical appointment transcripts. These conversations often contain nuanced emotional, psychological, and decision-making cues that structured data alone cannot capture.
Goals:
- Identify early markers of emotional hesitation, confusion, or doubt
- Extract contextual signals (e.g., language tone, sentiment, agency) that correlate with later regret
- Improve prediction in borderline or ambiguous cases
This fusion of numerical data and conversational context will create a more holistic model—one that not only detects risk but also understands the human experience behind it.
Acknowledgments
We are deeply grateful to:
- Dr. Erika Ramsdale and her team at the University of Rochester Wilmot Cancer Institute for their clinical guidance and mentorship
- Dr. Cantay Caliskan and Dr. Ajay Anand for their instruction, feedback, and support throughout the capstone experience
- The faculty and staff of the Goergen Institute for Data Science and Artifical Intelligence, whose commitment to interdisciplinary collaboration made this work possible
Their combined expertise, encouragement, and vision helped shape this project into one that bridges data science and compassionate care.
References
- Brehaut, J. C., O’Connor, A. M., Wood, T. J., Hack, T. F., Siminoff, L., Gordon, E., & Feldman-Stewart, D. (2003). Validation of a decision regret scale. Medical Decision Making, 23(4), 281–292.
- Calderón, C., Ferrando, P. J., Lorenzo-Seva, U., Higuera, O., Ramón y Cajal, T., Rogado, J., & Jiménez-Fonseca, P. (2019). Validity and reliability of the Decision Regret Scale in cancer patients receiving adjuvant chemotherapy. Journal of Pain and Symptom Management, 57(4), 828–834.
- Papadopoulou, A., Govina, O., Tsatsou, I., Mantzorou, M., Mantoudi, A., Tsiou, C., & Adamakidou, T. (2022). Quality of life, distress, anxiety and depression of ambulatory cancer patients receiving chemotherapy. Medical Pharmacy Reports, 95(4), 418–429.