Team
- Sydney Haupt – Hardware
- Boning Wang – Verification / QA
- Yongyi Zang – Software
Mentors
Professor Michael Heilemann, Professor Daniel Phinney, Professor Sarah Smith, Tre DiPassio
TL;DR
We designed a system that includes both hardware and software components to extract speech audio from a mixture of speech and music in real-time.
First, Let’s Hear the Results
This is the “ideal” scenario, the ground-truth signal:
Word Error Rate (WER): 6.92 %
Before putting through our system:
Word Error Rate (WER): 100.00 % (Computer can’t understand anything)
After putting through our system:
Word Error Rate (WER): 10.95 %
In this example, All Word Error Rate (WER) experiments are ran using OpenAI Whisper [4], current state-of-the-art automatic speech recognition (ASR) system. In other words, computer can better understand this speech now – almost as if the music interference does not exist!
Abstract
When we play music to and record speech from a flat panel speaker at the same time, the recorded speech will have music interference. The music interference will hurt performance in speech recognition, which is essential to smart speakers. To solve this problem, we propose an end-to-end echo cancellation device to remove the music interference. The device involves an echo-cancelation algorithm implemented on a Teensy USB Development Board as well as hardware interfacing between the flat panel speaker and Teensy.
Motivation
Signal Flow
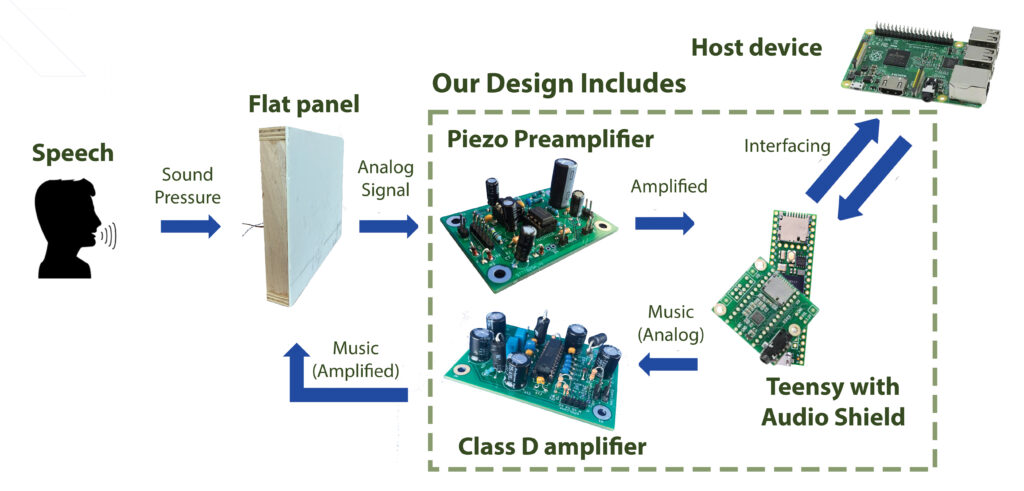
As illustrated in Figure 1 (and in above motivation video), Flat panel is working as both music speaker and microphone. This means the signal the on-panel microphone captures will naturally contains the music that’s playing.
Our system contains the hardware amplifiers for both music speaker and microphone, so we can play music to the panel and get signal from the panel; both signals will then be sent to our software, where our algorithm tries to separate the speech out. The separated speech will be send to the host device.
Echo Cancelation Algorithm
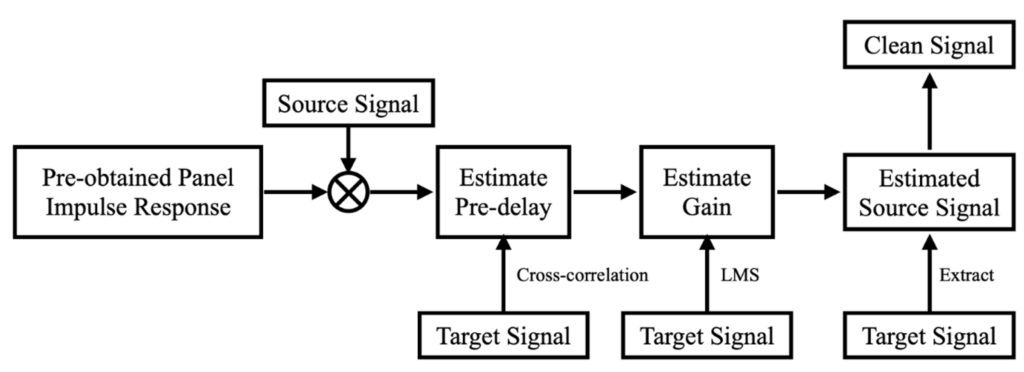
Estimation happens in the time domain (temporal) and the frequency domain (spectral) separately.
What we have in our hands are recorded signal which is a mix of speech and music echo, and source music signal. First of all, we convolve the source music signal with the inpulse response on the flat panel. After that, we use cross correlation algorithm to estimate the difference in time of the convolved signal and the music contained in recorded signal in order to align the two signals. Next, we use LMS algorithm to estimate the gain that should be applied to the signal we have in order to make the amplitude of the signal being processed as close of that of the music contained in recorded signal. Now we have approximated the music echo that should be substracted from the recorded signal, and the last step is to substract it and get the clean speech signal. This process is as illustrated in Figure 2.
Implementation
Software: Audio Stream Objects [1]
Convolve: Estimate the spectral domain interference with double overlap-add.
Align: Estimate the time domain interference using cross correlation.
Optimal Gain: Estimate the energy loss in transit.
Hardware: System Design
Piezo Preamplifier [2] boosts the signal from a piezo sensor on the flat panel to line-level for processing by the Teensy, while keeping signal within a safe range to protect the Teensy audio shield from excessive signals. A switch controlled by the Teensy applies a gain of one when music is playing, or a gain of three without music.
Class D Amplifier receives music at line-level from the Teensy and boosts it to a higher amplitude before sending the music to the driver. The amplifier is designed for stereo, 4Ω drivers. The TPA3122D2N class D chip [3] is used, which provides mute, shutdown, and gain controls that are set using Teensy’s GPIO.
Power System receives 18VDC, 49W from a wall AC/DC adapter, selected for the class D amplifier’s power requirement. This is reduced to 9VDC through a linear voltage regulator to power the preamplifier.
Bypass option is available for both the input and the output of the system, allowing users to apply the echo cancellation algorithm to any other smart speaker system. Users may connect their own microphone and preamp at the input, or their own amplifier and driver at the output.
Key Metrics
End-to-End Processing Latency: Time elapsed between when the signal is received by Teensy and when it is processed and ready to be output.
Music Reduction Quality: Difference in the level of music interference between processed and unprocessed signal.
Word Error Rate (WER) : Percentage of words that are not correctly recognized by automatic speech recognition (ASR) system on the host device. OpenAI Whisper [4] was selected as the ASR system.
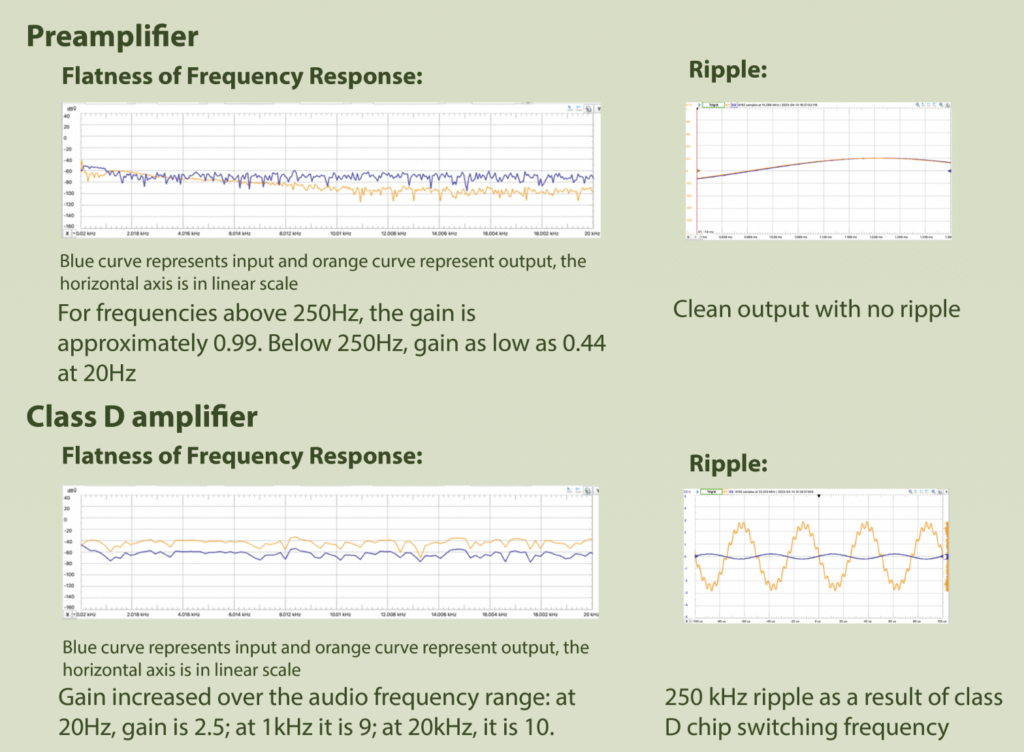
Flatness of Frequency Response: Identify any boost or attenuation in the audio frequency range as introduced by the hardware system.
Ripple/Output Noise: Noise introduced to output signal by components of amplifiers.
Results
Software Results
End-to-end Processing Latency: 2 frames of audio (5.8 ms).
Music Reduction Quality: music reduction quality significantly improved (as can be heared in the above demo)
Word Error Rate (WER): In software simulation, we achieved comparable WER to clean speech level, around 3%. During in-the-wild experiments on real-world collected data, we noticed that although WER is significantly improved, some part of speech is still recognized as non-speech, therefore not transcribed. We suspect this has something to do with the non-linearity of the system.
Hardware Results
Acknowledgements
We would like to thank Michael Heilemann, Daniel (Dan) Phinney, Sarah Smith, Joseph (Tre) DiPassio III, Paul Osborme, Seth Roberts, Sanaa Finley, Alex Kim, Cassius (Cash) Close, and Jessica (Jessa) Luo for their generous mentorship, guidance, and support.