Authors: Caelan Clayton, Veena Laks, Ramneek Nandha, Aabha Pandit
Advisor: Ajay Anand, Ph.D. Sponsor: Akkadian, LLC.; Jessica Gleason, Ph.D. and Jon Schlecht, BAS
Introduction
Pedagogy, the study of effective teaching practices, is supported by a growing body of research. Extensive work has been done in areas such as assessment design, student engagement, culturally responsive teaching, and now, the use of artificial intelligence in education. However, much of this research remains underutilized in higher education, especially as instructors face time and cognitive constraints when designing courses.
For instructional syllabus design, existing Artificial Intelligence (AI) tools, such as Large Language Models (LLMs) focus on generating content rather than guiding alignment with evidence-based practices. Additionally, these systems often generate responses that are not grounded in reliable pedagogical sources. This gap highlights the lack of accessible tools for instructors that translate pedagogical research into course design guidance.
To address this gap, we collaborated with Akkadian to create a web-based AI syllabus builder that uses retrieval augmented generation (RAG) to provide feedback on syllabus content and answer general pedagogy and institution-specific questions. Our system retrieves relevant information from a curated knowledge base of pedagogical and institutional resources and uses an LLM to generate context-aware feedback.
Data
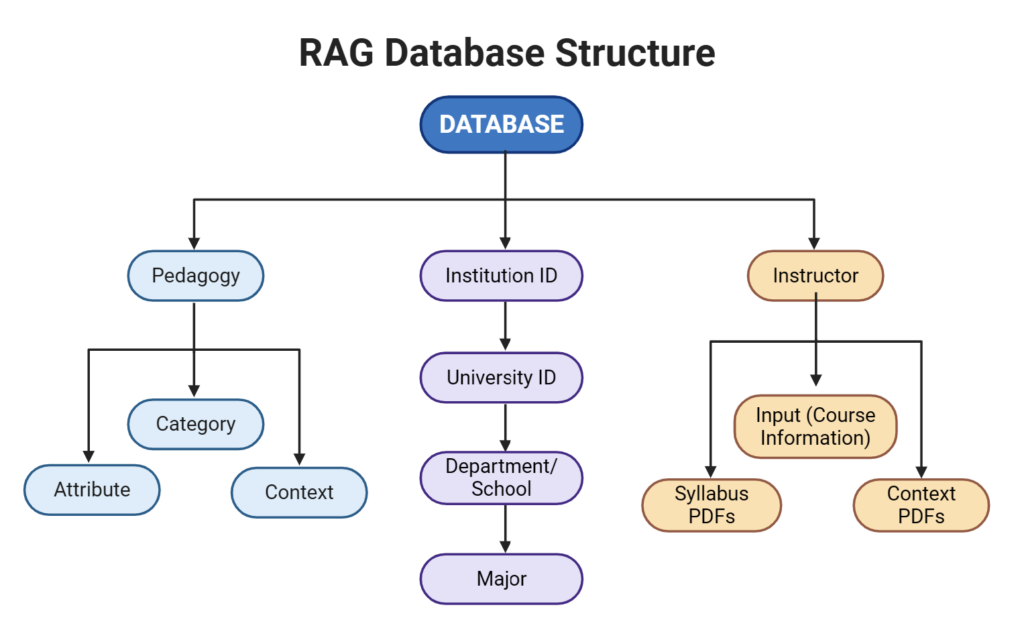
Akkadian’s long-term vision for their knowledge base is a multi-layered database that captures three different types of documents and their relationships. This serves as the foundation for retrieval and allows the system to generate responses that enforce best pedagogical practices and school policy constraints.
Pedagogy layer: consists of three core components: categories, attributes, and contexts. Categories define broad pedagogical concepts (e.g. assessment, engagement, and instructional strategy). Attributes specify how these concepts are applied in practice (e.g., active learning or lecture-based instruction). Contexts define situations where attributes are appropriate (e.g. online course, discipline, higher vs. lower level classes).
Institution layer: captures hierarchical information such as institution, internal departments/majors and is intended to ensure that generated responses align with institution-specific requirements.
Instructor layer: stores course-specific inputs such as course metadata and syllabus contents to allow for more tailored responses.
While Akkadian’s full database architecture remains under development, our work focuses on creating a functional approximation for testing our RAG system. Specifically, we implemented a simplified knowledge base that reflects the intended structure through the use of metadata and hierarchical organization. Documents were grouped into pedagogy and institutional layers, and further annotated with attributes such as subject domain (e.g. mathematics, music, psychology) and subject type (objectives, policies, assignments). This allowed us to simulate the category-attribute-context relationships and enable targeted retrieval.
Model (RAG Pipeline)
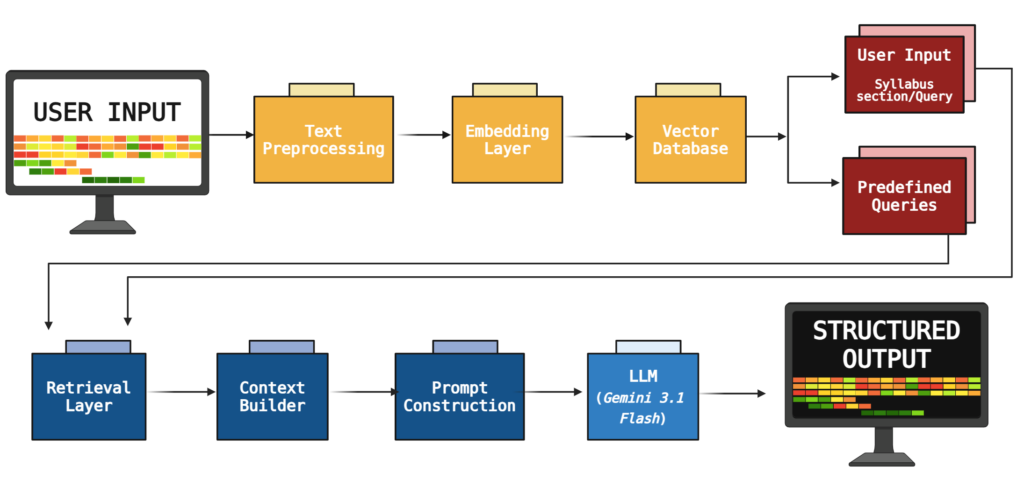
Retrieval Augmented Generation (RAG) is the process of optimizing the output of a LLM so it references an authoritative knowledge base outside of its training data sources before generating a response. Our system follows this framework to generate structured, pedagogically grounded feedback from syllabus inputs.
The pipeline begins by processing user input (either a syllabus section or a teaching question) and expanding it with task-specific query templates to improve retrieval, especially when user wording differs from the knowledge base.
All documents are preprocessed into overlapping chunks, embedded as vectors, and stored with metadata in a FAISS index. Using the expanded queries, the system retrieves semantically similar chunks across three separate sources: subject-specific pedagogy, general pedagogy, and institutional documents. This multi-layer retrieval ensures balanced representation rather than reliance on a single source.
The retrieved chunks are then filtered through deduplication to produce a concise, representative context. This context, along with the original input and task type, is used to construct a structured prompt that guides the LLM. The LLM generates a response grounded in the selected evidence and the output is formatted based on the task (either detailed feedback or concise answers) and includes references to source material.
Challenges
During development, several key challenges were addressed to improve the system.
Our initial retrieval system relied on a simple similarity search, which produced weakly relevant results. This was improved by introducing task-specific query expansion, which led to more relevant results. Another issue was a lack of diversity in the retrieved content because results were often dominated by one source. This was improved through multi-source balancing. Lastly, the system was expanded from only syllabus section feedback to also support general question answering, with interface improvements to guide retrieval.
Remaining limitations include the size of the knowledge base, integration with the database and webpage, and reliance on automated evaluation.
Evaluation
To evaluate the effectiveness of the proposed system, we measure performance across four metrics: recall, precision, faithfulness, and relevance. These metrics are designed to capture both stages of the RAG pipeline.
The system was evaluated using five benchmark tasks (three review-based and two question-answering), each with predefined pedagogical attributes that serve as a reference for expected output.
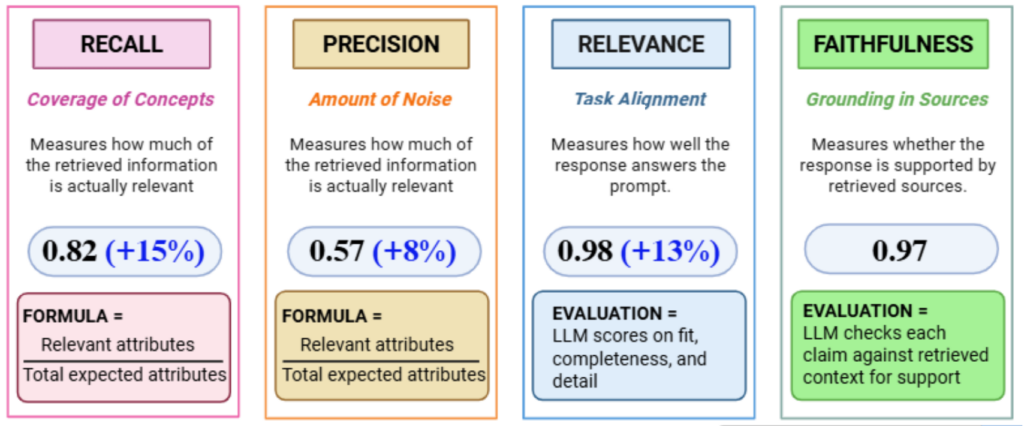
The results show strong improvements across most metrics. Recall increased significantly (0.67 → 0.82), so the system is able to capture more relevant pedagogical concepts due to query expansion and improved metadata. Precision rose moderately (0.49 → 0.57), which reflects a trade-off where broader retrieval improves coverage but introduces some less relevant information. On the generation side, relevance (0.98) and faithfulness (0.97) remain very high, indicating that responses are both well-aligned with the task and grounded in retrieved content..
Overall, the results highlight strong alignment between retrieval and generation, prioritizing comprehensive outputs over strict filtering of information.
Example
A sample question provided by Akkadian was: “What is culturally responsive teaching, and why is it important?”
The system generates a structured response that defines the concept, explains its significance, provides practical guidance, and suggests next steps. As shown in the image, the response includes direct citations to the sources used, along with specific page and paragraph references.

To further evaluate system behavior, we tested how the chatbot responds when asked for specific examples that are not present in the knowledge base. In this case, the available sources on culturally responsive teaching did not include concrete classroom examples. When prompted for implementation examples and outcomes, the system correctly avoided hallucinating information. Instead, it explicitly stated that the sources did not provide a detailed case study:
“While the provided references define the concept and its goals, they do not provide a specific, detailed classroom scenario or case study to serve as a concrete example of implementation.”
This behavior demonstrates that the system remains faithful to its sources and does not generate unsupported claims when information is unavailable.
Conclusion
This project demonstrates the effectiveness of a Retrieval-Augmented Generation system for providing pedagogically grounded syllabus feedback. By integrating a curated knowledge base with a structured retrieval pipeline and prompt-guided language model generation, the system is able to produce responses that are both relevant and informed by established educational practices.
Evaluation results show strong performance in recall, relevance, and faithfulness, indicating that the model captures key pedagogical concepts and effectively applies them to generated responses, while lower precision reflects a deliberate focus on diverse coverage.
Overall, this project highlights the potential of integrating generative AI with pedagogical practices to support instructors in course syllabus design. Future improvements include expanding the knowledge base, automating metadata, refining retrieval strategies, and incorporating instructor-specific materials to further enhance accuracy and personalization.
Acknowledgements
We would like to extend our sincere gratitude to Jessica Gleason and Jon Schlecht from Akkadian for sponsoring and facilitating this project with valuable resources and mentorship. We also gratefully acknowledge Professor Ajay Anand for his insightful guidance and feedback during our meetings that helped shape the direction of our project.